ローカル環境で完結するAI写真検索の実装
今回はローカル環境で完結するAI写真検索を実装します.
看板に写った小さな文字や手書きノートの文字などGoogleフォトでは引っかからないような単語で高度な検索をしたり,クラウド上にアップロードしたくないような写真の検索をローカル環境で行うことができるようになります.
画像のラベル付けには1,000枚: 目安20分程度かかります. 一度,ラベル付けを済ませてしまえば,高速で検索できます.
※ 本ページでは,VRAM12GB以上のNVIDIA製GPU(RTX 3060 / 4070 / 3090 等)を使用することを前提としています.
(GTX 10シリーズ等の古いGPUでは動作しない場合があります)
【関連】大規模言語モデルによるコードの要約と検索システムの実装
LLMによるラベル付けとベクトルデータベースを使ったコード検索です.こちらはVRAM8GBでも動きます.
0. 推奨スペック
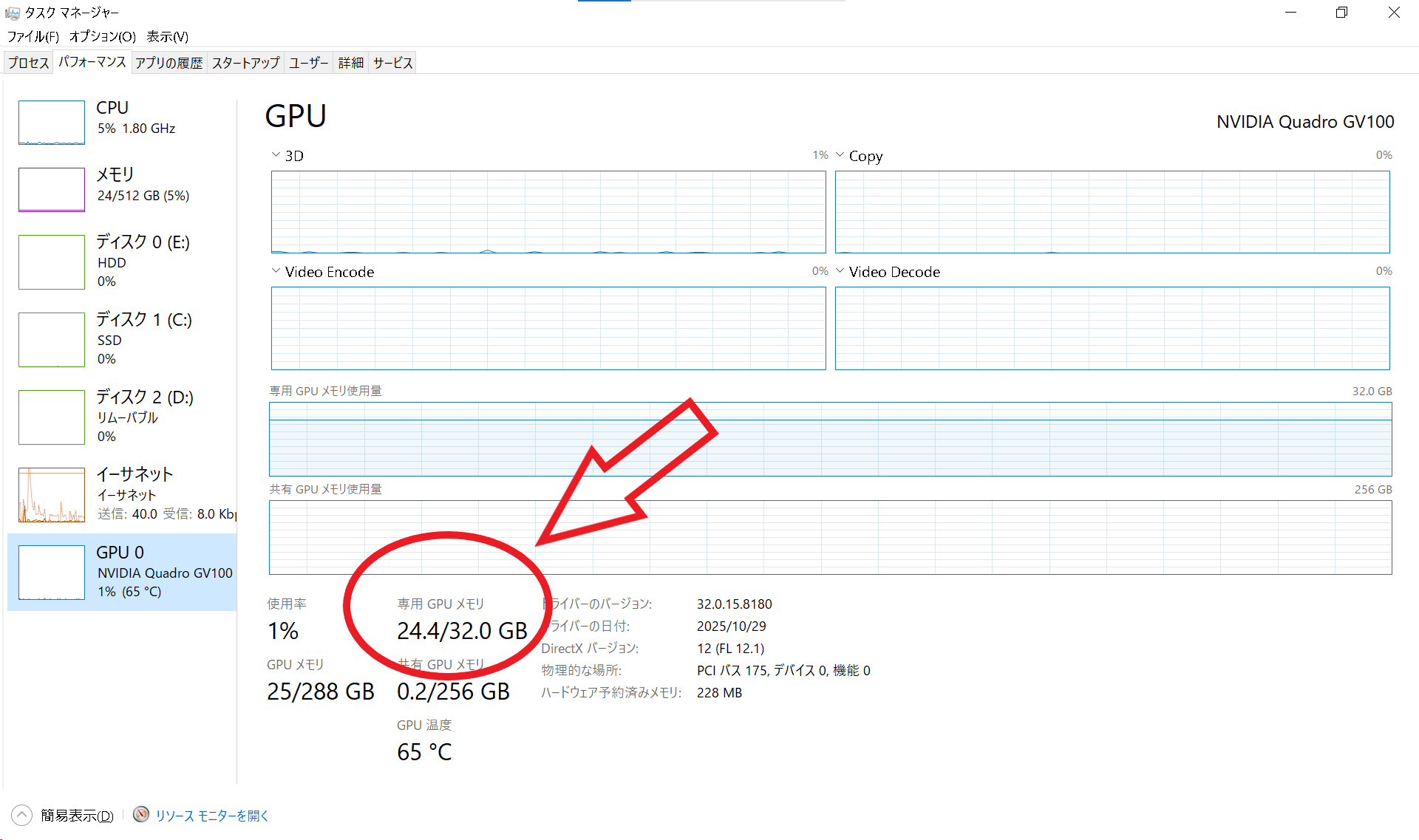
本システムはPythonライブラリの「vLLM」を使用して,画像認識モデル(Qwen2-VL)を動作させます. 画像認識はテキスト処理よりもVRAM(GPUメモリ)を多く消費するため,お使いのGPUスペックに合わせて適切なモデル(または量子化版)を選ぶ必要があります. 専用GPUメモリは「タスクマネージャー」->「パフォーマンス」->「GPU」から確認できます. ※ 共有GPUメモリではなく,必ず専用GPUメモリの容量を確認してください.
使用するモデル:Qwen2-VL-7B-Instruct
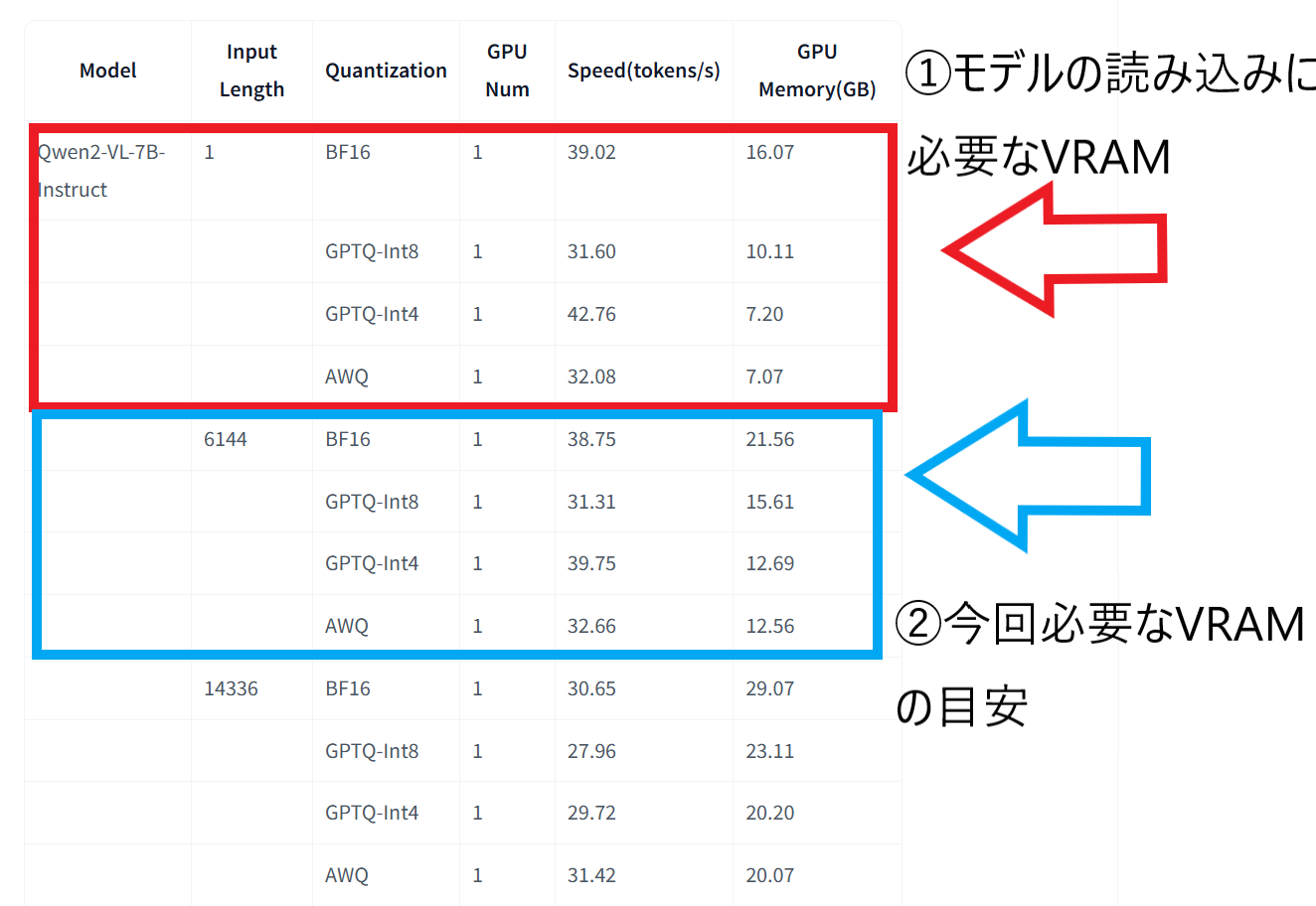
今回は7B(70億パラメータ)のモデルを使用します.GPUの専用GPUメモリに応じて,通常版か軽量版(AWQ)を使い分けてください.
2-1. 専用GPUメモリ 24GB以上(検証済み)
推奨設定: 通常版 (BF16):
MODEL_ID = "Qwen/Qwen2-VL-7B-Instruct"
RTX 3090 / 4090 / 5090 など
メモリに余裕があるため,最も精度が高く,かつ高速なfp16モードで動作します.解像度の高い画像でも安定して処理可能です.
2-2. 専用GPUメモリ 24GB未満
推奨設定: AWQ量子化版 (AWQ):
MODEL_ID = "Qwen/Qwen2-VL-7B-Instruct-AWQ"
RTX 3060(12GB) / 4070 / 4080 / 5080 など
残念ながら,通常版のモデルは起動だけで約15.5GBを消費するため,VRAM 16GBのGPUでもメモリ不足でエラーになります.
「AWQ」と呼ばれる軽量化されたモデルを指定することで,精度をほぼ落とさずにメモリ消費を半分程度(約7GB+α)に抑えて動作させることが可能です.
※ データを圧縮して読み込むため,処理速度は通常版よりわずかに落ちる場合がありますが,VRAM消費を劇的に抑えられます.
※ AWQ版は新しいGPU(Compute Capability 7.5以上)向けの技術です.GTX 1070/1080などのGTX 10シリーズ(Pascal世代)以前のGPUでは,VRAM容量に関わらず動作しません.
2-3. 専用GPUメモリ 8GB以下
動作困難な可能性があります. AWQ版を使えばモデル自体はロードできるかもしれませんが,画像を読み込んだ瞬間にメモリがあふれる(OOM)可能性が高いです. ※ AWQ版は新しいGPU(Compute Capability 7.5以上)向けの技術です.GTX 1070/1080などのGTX 10シリーズ(Pascal世代)以前のGPUでは,VRAM容量に関わらず動作しません.
1. 前準備:WSL2 (Windows Subsystem for Linux) の導入
本ページでは,Windows上でLinux環境を動かす「WSL2」という機能を使用します.
手順 1. インストールコマンドの実行
Windowsボタンを押し,PowerShell を 管理者として実行 をクリックして起動します. 以下のコマンドを入力して Enter キーを押してください.
wsl --install 処理が完了したら,必ずパソコンを再起動してください.
手順 2. Ubuntuの初期設定
再起動後,自動的に「Ubuntu」という黒い画面が立ち上がり,インストールが続きます. しばらく待つと,ユーザー名とパスワードの設定を求められます.
- Enter new UNIX username: 好きな名前を英字で入力(例:user)してEnter
- New password: 好きなパスワードを入力してEnter
Linuxの仕様上,パスワードを入力しても画面には
*** や ●●● が一切表示されません.
文字が表示されなくても入力は受け付けられているので,入力が終わったらEnterキーを押してください.
手順 3. エラーが出る場合
もし,wsl --install でエラーが出る場合,パソコンのBIOS設定で「仮想化機能」が無効になっている可能性があります.
お使いのPCメーカーやマザーボードの説明書を確認し,BIOS画面から仮想化を「Enable(有効)」にしてください.
【参考(外部サイト)】【WSL2インストール奮闘記】BIOS設定がカギだった話
インストール後のトラブル
Zone.Identifierが鬱陶しい Linuxコマンドがわからないなどのトラブルがある場合はこちらのサイトが分かりやすくまとまっています.
【参考(外部サイト)】 WSL2 のインストールとアンインストール
2. 仕様と作成手順
ユーザーの入力したキーワードと一致する情報を持つ写真を一覧で表示するようなものを作ります.
写真に写った小さな文字まで事細かに認識させたり,写真の状況について詳しく説明させるため,Googleフォトでは出てこないような写真まで探し出せるようになります.
今回,AIを使うのはラベル付けの部分だけです.
手順1. ラベル付け Qwen2-VL-7B-Instructに分類(写真・スクリーンショット・イラストなど) タグ(場所・人物・風景など) 説明(状況の詳細な説明) 文字(看板に書かれた文字など)をJSONで生成させラベル付けします.
手順2. 検索 ユーザーの入力したクエリに対して,部分一致検索を行い写真の一覧を返します.
出力されるJSONの例
{"category": "Photo", "tags": ["書斎", "本棚", "デスクトップパソコン", "扇風機"], "description": "この画像は日本の個人的な書斎の一隅を示しています。右側には大きな扇風機が立っており、その前にはいくつかの電子機器と本が置かれています。左側には木製の椅子があり、その上にはタオルや紙物などが敷かれていました。背景には多くの本が並んでいて、一部は机の上のものも含まれます。", "ocr_text": [], "file_path": "素材/sample.jpg"}
3. WSL上でのPython環境のセットアップ(※WindowsのPythonは使いません)
WSL2(Ubuntu)の初期状態では,ライブラリを管理するツール(pip)が入っていなかったり,直接インストールしようとするとエラーが出たりします. トラブルを避けるため,以下のコマンドを順番に実行して,Pythonの仮想環境(venv)を作成します. ※ 以下の作業はコマンドプロンプトやPowerShellでなく必ず「WSL2 (Ubuntu)」のターミナルで実行してください.
3-1. 必要なツールのインストール
まずは,pipとvenv(仮想環境作成ツール)をインストールします.
(パスワードを聞かれたら,設定したパスワードを入力してください.文字は表示されませんが,入力されています.)
sudo apt update && sudo apt install -y python3-pip python3-venv 3-2. 仮想環境の作成と有効化
プロジェクト用のフォルダを作り,その中に隔離された環境を作ります.
今後は毎回,作業を始める前にこの「source ...」コマンドを実行することになります.
# フォルダを作って移動
mkdir my_photo_search
cd my_photo_search
# 仮想環境(my_venv)を作成
python3 -m venv my_venv
# 仮想環境を有効化(行の先頭に (my_venv) と表示されれば成功!)
source my_venv/bin/activate
3-3. ライブラリのインストール
Pythonでプログラムを実行するために必要なライブラリをpipでインストールします.(動作確認済みのバージョンを指定しています)
今回インストールが必要なのはラベル付け用の推論エンジン「vLLM」と画像処理(リサイズ)用の「Pillow」 検索アプリ表示用の「streamlit」の3つだけです.
「WSL2 (Ubuntu)」のターミナルで以下のコマンドを実行してください.
pip install vllm==0.12.0 streamlit==1.52.2 pillow==12.0.0
4. ファイルとフォルダの配置
プログラムを動かすために,ファイルや画像フォルダを以下のように配置します.
WSL2のホームディレクトリ(~/my_photo_search/)の中が,最終的に以下のようになっている状態を目指します.
「WSL2 (Ubuntu)」のターミナル で 「explorer.exe .」と打ち込めばファイルエクスプローラーが開くのでファイルを配置してください.
※ キーワードで検索できるようになるので古い写真やなるべくたくさんの写真を入れると面白いと思います.画像データや解析内容が外部のサーバーに送信されることはありません.
explorer.exe .
my_photo_search/ ├── images/ <-- 【重要】検索したい画像を詰め込むフォルダ
│ ├── photo01.jpg
│ ├── screenshot.png
│ └── ... (大量の画像)
├── update_db.py <-- (手順5で作成) 画像を解析してDBを作るプログラム
└── search_app.py <-- (手順6で作成) 検索して結果を表示するプログラム 準備手順
-
画像フォルダの準備:
imagesという名前のフォルダを作成し,その中に検索対象にしたい写真をすべてコピーしてください. -
スクリプトの作成:
この後紹介するPythonコードを,それぞれ
update_db.pyとsearch_app.pyという名前で保存します.
5. DBの作成 (update_db.py の実行)
(my_env) user@DESKTOP-ABCDEFG:~/my_photo_search$ のように表示されていることを確認してください. 表示されていない場合は以下のコマンドで仮想環境を有効化します.
source my_env/bin/activatephoto_search.db に写真のラベル付けデータが保存されていきます.
※ 初回実行時は,数GBのモデルデータをダウンロードするため少し時間がかかります.
※ 「WSL2 (Ubuntu)」のターミナル で実行してください.
python update_db.py
import sqlite3
from vllm import LLM, SamplingParams
from PIL import Image
import os
import glob
import json
import re
import time
# ==========================================
# 設定
# ==========================================
IMAGE_FOLDER = "images"
DB_FILE = "photo_search.db"
MODEL_ID = "Qwen/Qwen2-VL-7B-Instruct"
# MODEL_ID = "Qwen/Qwen2-VL-7B-Instruct-AWQ" # VRAM24GB未満の場合
# 一度にvLLMに投げる枚数(こまめに保存するため)
BATCH_SIZE = 50
SYSTEM_PROMPT = """<|vision_start|><|image_pad|><|vision_end|>
この画像を詳細に分析し,以下のJSON形式のみを出力してください.
Markdownのコードブロックは不要です.
{
"category": "Photo" または "Screenshot" または "Illustration",
"tags": ["被写体", "色", "雰囲気", "場所", "文字の内容"],
"description": "画像の内容についての具体的で詳細な説明(3文以上)",
"ocr_text": ["画像内の文字", "看板", "メニュー"]
}
"""
# ==========================================
# DB周りの関数
# ==========================================
def init_db():
"""DBとテーブルを作成"""
conn = sqlite3.connect(DB_FILE)
c = conn.cursor()
# file_path を主キーにして重複を防ぐ
c.execute('''CREATE TABLE IF NOT EXISTS images (
file_path TEXT PRIMARY KEY,
category TEXT,
tags TEXT,
description TEXT,
ocr_text TEXT,
processed_at TIMESTAMP DEFAULT CURRENT_TIMESTAMP
)''')
conn.commit()
conn.close()
def get_processed_files():
"""すでにDBにあるファイルパスのリストを取得"""
conn = sqlite3.connect(DB_FILE)
c = conn.cursor()
c.execute("SELECT file_path FROM images")
# WindowsパスとLinuxパスの揺れを吸収するため,正規化してセットに入れる
processed = {os.path.normpath(row[0]) for row in c.fetchall()}
conn.close()
return processed
def save_batch(results):
"""結果のリストをまとめてDBに保存"""
conn = sqlite3.connect(DB_FILE)
c = conn.cursor()
c.executemany('''INSERT OR REPLACE INTO images
(file_path, category, tags, description, ocr_text)
VALUES (?, ?, ?, ?, ?)''', results)
conn.commit()
conn.close()
# ==========================================
# JSON抽出・整形ロジック
# ==========================================
def safe_extract_json(text):
"""AIの出力からJSON部分だけを抜き出し,タグなどを安全に整形する"""
try:
# 1. 正規表現で { ... } を抜き出す
match = re.search(r'(\{.*\})', text, re.DOTALL)
if not match:
return None
data = json.loads(match.group(1))
# 2. タグの安全化(辞書が混じっていたら文字列にする)
raw_tags = data.get("tags", [])
safe_tags = []
if isinstance(raw_tags, list):
for t in raw_tags:
if isinstance(t, str):
safe_tags.append(t)
else:
safe_tags.append(str(t)) # 強制文字列化
# 3. DBにはリストを入れられないのでJSON文字列にして格納
return {
"category": str(data.get("category", "Unknown")),
"tags": json.dumps(safe_tags, ensure_ascii=False),
"description": str(data.get("description", "")),
"ocr_text": json.dumps(data.get("ocr_text", []), ensure_ascii=False)
}
except:
return None
# ==========================================
# メイン処理
# ==========================================
def main():
init_db()
# 1. 画像収集
print(f"フォルダ内を走査中: {IMAGE_FOLDER}")
extensions = ["*.jpg", "*.jpeg", "*.png", "*.JPG", "*.JPEG", "*.PNG"]
all_files = []
for ext in extensions:
all_files.extend(glob.glob(os.path.join(IMAGE_FOLDER, "**", ext), recursive=True))
all_files = sorted(list(set(all_files)))
# 2. 済みファイルをスキップ
processed_files = get_processed_files()
target_files = [f for f in all_files if os.path.normpath(f) not in processed_files]
print(f"全ファイル: {len(all_files)} 枚")
print(f"処理済み: {len(processed_files)} 枚")
print(f"今回処理対象: {len(target_files)} 枚")
if not target_files:
print("すべての画像が処理済みです.")
return
# 3. エンジン起動
print("vLLMエンジンを起動中...")
llm = LLM(
model=MODEL_ID,
trust_remote_code=True,
dtype="float16",
gpu_memory_utilization=0.8, # GPU専用メモリの割り当て
max_model_len=4096 # 数字を大きくするとVRAM使用量が上がります
)
sampling_params = SamplingParams(
temperature=0.05, # 安定した出力が欲しいのでtemperatureは低め
max_tokens=1024,
repetition_penalty=1.15 # OCRで単語を繰り返すことがあるので繰り返しにペナルティを設定
)
# 4. バッチ処理ループ
# target_files を BATCH_SIZE ずつに区切って処理
total_batches = (len(target_files) + BATCH_SIZE - 1) // BATCH_SIZE
print(f"処理開始! ({BATCH_SIZE}枚ごとにDB保存します)")
for i in range(0, len(target_files), BATCH_SIZE):
batch_paths = target_files[i : i + BATCH_SIZE]
current_batch_num = (i // BATCH_SIZE) + 1
print(f"Batch {current_batch_num}/{total_batches} 処理中... ({len(batch_paths)}枚)")
prompts = []
valid_paths = []
# 画像読み込み
for path in batch_paths:
try:
# そのままのサイズを入力とするとメモリを大量に食うのでリサイズする
image = Image.open(path).convert("RGB")
image.thumbnail((1024, 1024), Image.Resampling.LANCZOS)
prompts.append({
"prompt": SYSTEM_PROMPT,
"multi_modal_data": {"image": image}
})
valid_paths.append(path)
except Exception as e:
print(f"Error loading {path}: {e}")
if not prompts:
continue
# 生成
outputs = llm.generate(prompts, sampling_params)
# 結果整形
db_data = []
for path, output in zip(valid_paths, outputs):
raw_text = output.outputs[0].text.strip()
parsed = safe_extract_json(raw_text)
if parsed:
db_data.append((
path,
parsed["category"],
parsed["tags"], # JSON文字列
parsed["description"],
parsed["ocr_text"] # JSON文字列
))
else:
# パース失敗時も一応DBに入れておく
db_data.append((
path, "Error", "[]", raw_text, "[]"
))
# DB保存
save_batch(db_data)
print(f" -> DBに保存しました.")
print("="*30)
print("全処理完了!")
if __name__ == "__main__":
main()
6. 検索アプリ(search_app.py)の作成と起動
作成したDB(photo_search.db)を使って写真の検索をしてみます.
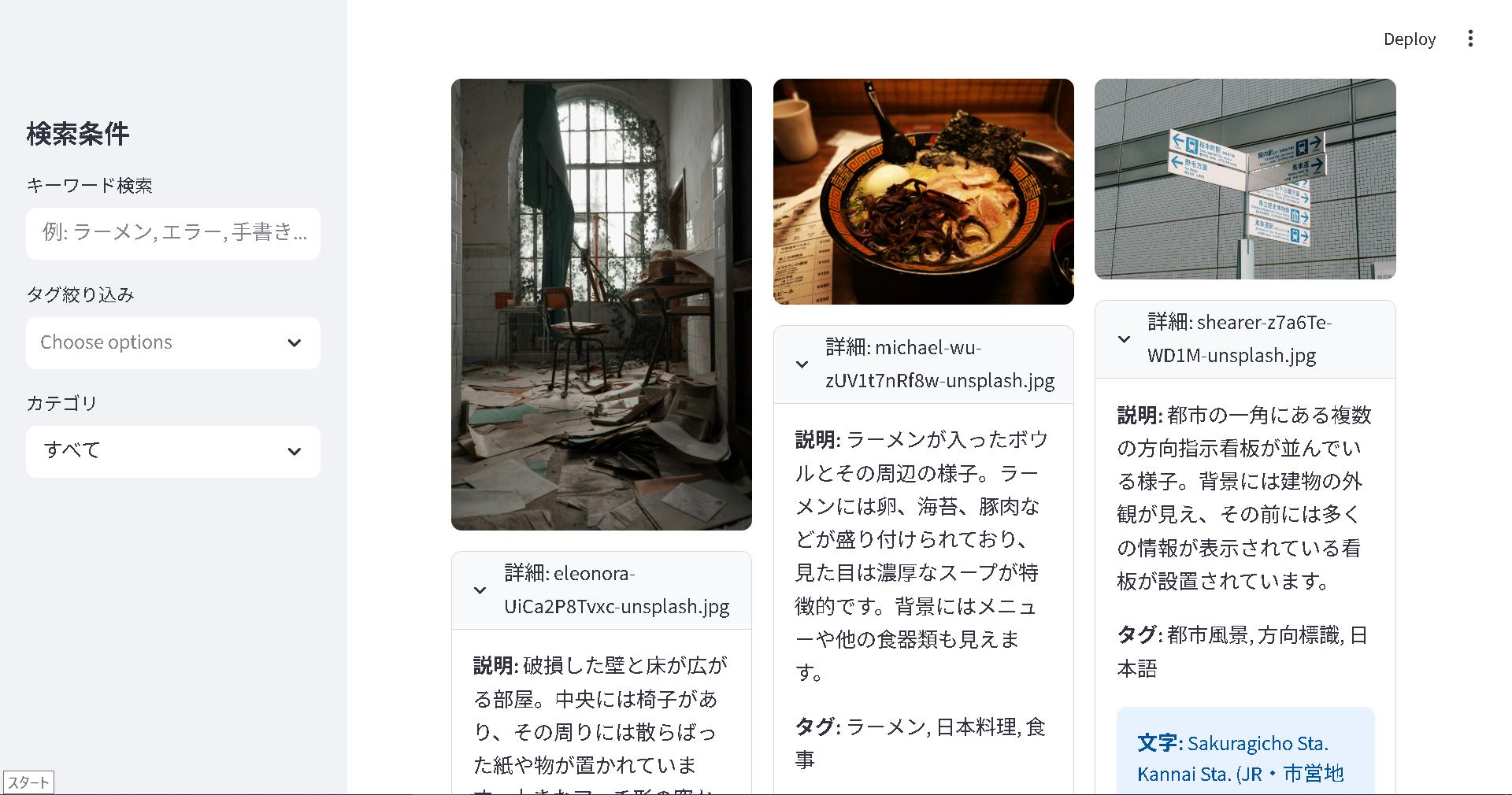
画像のように表示されれば成功です.
実行時の注意(重要)
このプログラムだけは,実行コマンドが特殊です.
python ... ではなく,streamlit run ... というコマンドを使います.間違えると起動しません.
streamlit run search_app.py
import streamlit as st
import sqlite3
import json
import os
from PIL import Image
# ==========================================
# 設定
# ==========================================
st.set_page_config(layout="wide", page_title="AI写真検索(DB版)")
DB_FILE = "photo_search.db"
BASE_IMAGE_DIR = "." # 画像のルートパス
# ==========================================
# データ読み込み関数 (DB版)
# ==========================================
# DBはキャッシュせず,都度クエリを投げても速いが,検索用に全件ロードして扱う
@st.cache_data
def load_data_from_db():
if not os.path.exists(DB_FILE):
return []
conn = sqlite3.connect(DB_FILE)
conn.row_factory = sqlite3.Row # カラム名でアクセスできるようにする
c = conn.cursor()
c.execute("SELECT * FROM images")
rows = c.fetchall()
conn.close()
data = []
for row in rows:
# DBから取り出したデータを使いやすい辞書形式に変換
item = dict(row)
# JSON文字列で保存されているカラムをリストに戻す
try:
item["tags"] = json.loads(item["tags"])
except:
item["tags"] = []
try:
item["ocr_text"] = json.loads(item["ocr_text"])
except:
item["ocr_text"] = []
# OCRテキストを検索用に結合
ocr_list = [str(x) for x in item["ocr_text"]]
item["ocr_search_text"] = " ".join(ocr_list)
data.append(item)
return data
# ==========================================
# メイン処理
# ==========================================
def main():
st.title("AI写真検索 (SQLite版)")
st.caption("Powered by Qwen2-VL")
all_images = load_data_from_db()
if not all_images:
st.warning(f"データベース({DB_FILE})が見つかりません.update_db.py を実行してください.")
return
# --- サイドバー ---
st.sidebar.header("検索条件")
search_query = st.sidebar.text_input("キーワード検索", placeholder="例: ラーメン, エラー, 手書き...")
# タグ一覧の作成
all_tags = set()
for img in all_images:
for tag in img["tags"]:
all_tags.add(tag)
selected_tags = st.sidebar.multiselect("タグ絞り込み", sorted(list(all_tags)))
categories = list(set([img["category"] for img in all_images]))
selected_category = st.sidebar.selectbox("カテゴリ", ["すべて"] + categories)
# --- 検索ロジック ---
filtered_images = []
for img in all_images:
# 検索対象テキスト
content_text = (
str(img["description"]) + " " +
" ".join(img["tags"]) + " " +
str(img["ocr_search_text"])
).lower()
# フィルタリング
if selected_category != "すべて" and img["category"] != selected_category:
continue
if selected_tags:
if not set(selected_tags).issubset(set(img["tags"])):
continue
if search_query:
keywords = search_query.lower().split()
if not all(k in content_text for k in keywords):
continue
filtered_images.append(img)
# --- 結果表示 ---
st.markdown(f"### Hit: {len(filtered_images)} 枚")
st.divider()
cols = st.columns(3)
for idx, img_data in enumerate(filtered_images):
col = cols[idx % 3]
with col:
file_path = img_data["file_path"]
if not os.path.exists(file_path):
file_path = os.path.join(BASE_IMAGE_DIR, os.path.basename(file_path))
try:
image = Image.open(file_path)
st.image(image, use_container_width=True)
with st.expander(f"詳細: {os.path.basename(file_path)}"):
st.write(f"**説明:** {img_data['description']}")
st.write(f"**タグ:** {', '.join(img_data['tags'])}")
if img_data['ocr_search_text']:
st.info(f"**文字:** {img_data['ocr_search_text'][:100]}...")
except:
st.error(f"Image not found: {os.path.basename(file_path)}")
if __name__ == "__main__":
main()
7. まとめ
今回はローカル環境でvLLMを使ってAI写真検索を実装しました.
ベクトルデータベースを使ったコード検索の実装もありますので,興味があればぜひこちらもご覧ください.
【関連】大規模言語モデルによるコードの要約と検索システムの実装
デモ画面に使用した画像
UnsplashのMichael Wuが撮影した写真
Unsplashのeleonoraが撮影した写真
UnsplashのShearerが撮影した写真