大規模言語モデルによるコードの要約と検索システムの実装
今回はローカル環境で大規模言語モデルにコードを要約させて検索できるようにするAIストレージ検索を実装しました.
ローカル環境で完結するので機密データを外部に出したくない人や,せっかく買ったGPUを活用してAIを動かしてみたいという人にオススメの構成になっています.
いきなり,PC内のたくさんのファイルに対して実行すると膨大な時間がかかるのでまずはお試しで検索システム検証用のコードを64件用意しましたので,必要であればこちらをダウンロード・解凍して使用してください.
検証用コードには以下の4種類が入っています.
- Easy: 分かりやすい変数名とコメント付き
- Normal: コメントを削除
- Hard: コメント削除 + 変数名や表示内容を匿名化
- EX: Hardに加え,ファイル名も匿名化
今回はこの検証用コード64件を使用して進めていきます.
【関連】ローカル環境で完結するAI写真検索の実装
ベクトルデータベースを使わずVLMによるラベル付け + 部分一致検索のシンプルな構成です.
WSL2の導入やVRAM12GB以上のNVIDIA製GPUが必須ですが,視覚的にはこちらの方が面白いかもしれません.
環境構築の難易度が本ページより若干高いです.
本ページで使用している技術の理論・参考サイト(クリックして展開)
本ページでは以下の技術を使用しています.理論的背景に興味がある方は参照してください.
1. ベクトル化 (Embeddings) & ベクトル検索
-
ベクトル化 / エンベディング(Embedding)|用語集 - HULFT
ベクトル化について分かりやすく解説されています. 本ページではローカル環境でベクトル化を行います. -
ベクトルデータベース(Vector database)|用語集 - HULFT
今回利用するベクトルデータベースについて解説されています.類似度の計算やRAGとの関係についても解説されています.
2. ローカルLLM & 量子化
-
量子化とは - IBM
今回使用する大規模言語モデルは量子化モデルです.量子化モデルについて解説されています.
1. 仕様と作成手順
ユーザーの入力したキーワードに対して関連度順にファイル一覧と要約を高速に返すものを作ります.
イメージとしてはChatGPTにコードにラベルを付けさせ,ラベルとコードのセットでGoogle検索を作るようなものです.
手順1. ラベル付け 指定したフォルダ内の全ファイル(適宜,除外ファイルを設定します)を大規模言語モデル qwen2.5-coder:14b に読ませ内容の要約とキーワードをJSON形式で出力させます.
手順2. ベクトル化 埋め込みモデル multilingual-e5-large に大規模言語モデルの生成したJSONとコードの全文を渡し,検索用ベクトルに変換させデータベースに保存します.
手順3. 検索 ユーザーの入力したクエリに対して,近傍検索を行い関連度の高いファイルの一覧を返します.
2. 推奨スペック
使用しているGPUの専用GPUメモリに応じて使用するモデルを変更したり,手順1(ラベル付け) を省略したりする必要があります.
2-1. GPUが使えない場合
手順2以降(ベクトル化のみ)であればCPUだけで十分に可能です. 手順2から実行してください. 60秒もあれば終わります.
2-2. GPUが使える場合
専用GPUメモリに応じて使用できるモデルが変わります.
以下は専用GPUメモリと使用できるモデルの目安です.
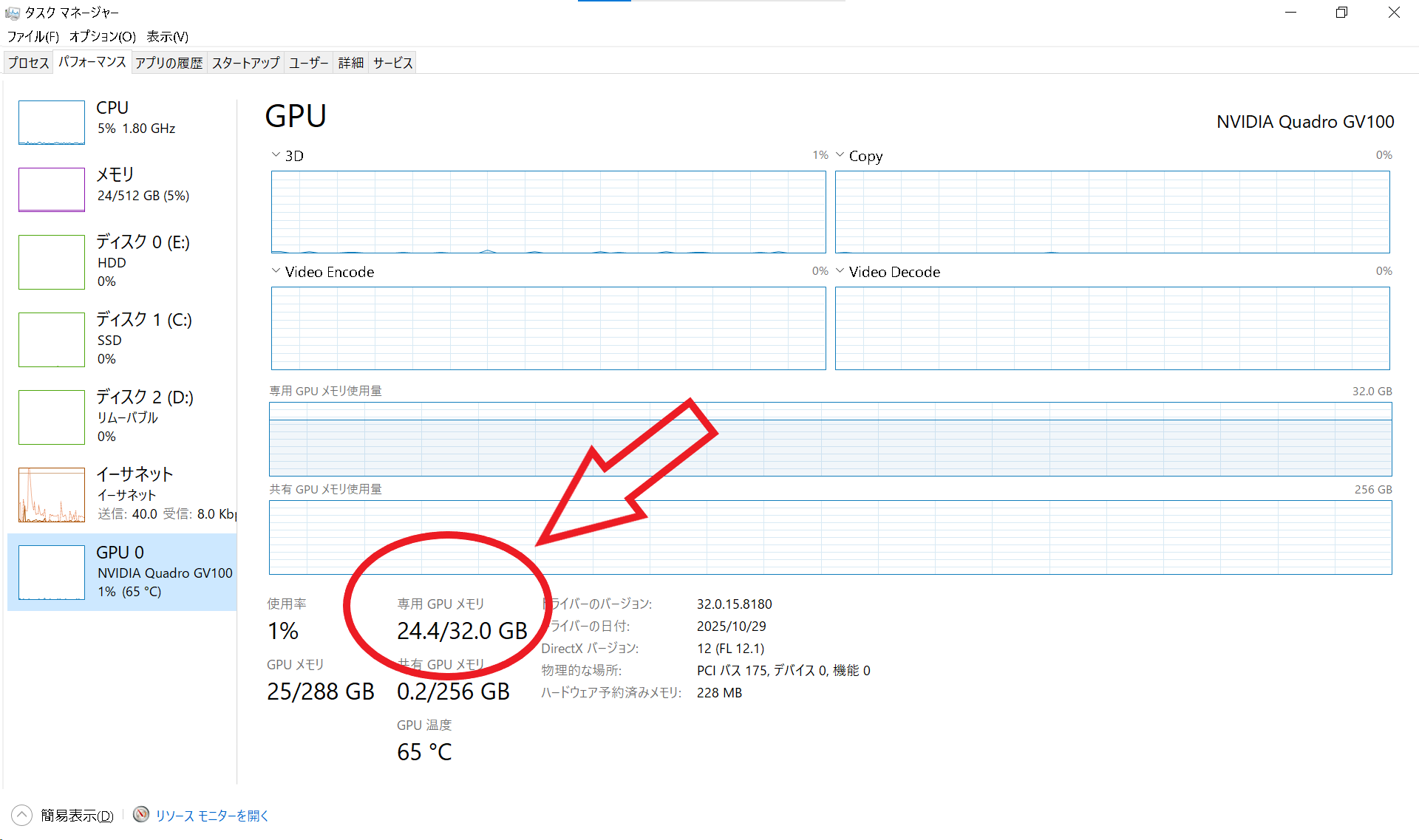
専用GPUメモリはタスクマネージャー -> パフォーマンス -> GPUから確認できます.
※ 共有GPUメモリやGPUメモリではなく必ず専用GPUメモリを確認してください.
モデルサイズの目安
SIZEの容量がモデルを動かすのに必要最低限必要なGPU専用メモリの目安になります.
C:\Users\user>ollama list
NAME ID SIZE MODIFIED
qwen2.5-coder:14b 9ec8897f747e 9.0 GB 21 hours ago
qwen2.5-coder:32b b92d6a0bd47e 19 GB 2 days ago
qwen2.5-coder:7b dae161e27b0e 4.7 GB 2 days ago
2-2-1. 専用GPUメモリ8GBの場合
Qwen2.5-Coder-7B + multilingual-e5-large で実行可能です. 今回使う簡単な検証用コードに対しては7Bでも十分綺麗な要約とキーワードを返してきますが,複雑なコードになると回答が不安定になります.
2-2-2. 専用GPUメモリ12GB~16GBの場合
Qwen2.5-Coder-14B + multilingual-e5-large で実行可能です. 今回の検証用コードだけでなく複雑なコードでも十分な精度で要約とキーワードを返してくれます.
2-2-3. 専用GPUメモリ24GB以上の場合
Qwen2.5-Coder-32B + multilingual-e5-large で実行可能です. 今回のAIストレージ検索にはオーバースペックかもしれません.
3. 要約用大規模言語モデルのダウンロード
要約用大規模言語モデルをダウンロードします. 今回は,ローカル環境でLLMを簡単に動かせるツール「Ollama」を使用します.
3-1. Ollamaのインストール
Ollamaの公式サイトにアクセスし,Downloadボタンからインストーラーをダウンロードして実行してください.
インストールは「Next」を押していくだけで完了します.
3-2. モデルのダウンロード(Pull)
インストールが完了したら,コマンドプロンプトを開き,スペックに合わせて以下のコマンドを実行してください.
ollama pull qwen2.5-coder:14b
4. 必要なライブラリのダウンロード
Pythonでプログラムを実行するために必要なライブラリをpipでインストールします.
コマンドプロンプトで以下のコマンドを実行してください.
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
pip install langchain langchain-community langchain-huggingface sentence-transformers chromadb ollama tqdm
最新のRTX 50シリーズは、上記のコマンドでは動作しない可能性があります。
エラーが出る場合は、以下のコマンド(Nightly版)を使用してください。
pip install --pre torch torchvision torchaudio --index-url https://download.pytorch.org/whl/nightly/cu128
pip install langchain langchain-community langchain-huggingface sentence-transformers chromadb ollama tqdm
PythonからGPUが認識されているかも確認します.
python -c "import torch; print(torch.cuda.get_device_name(0) if torch.cuda.is_available() else 'No GPU')"
- langchain関連: AIの処理を便利にするフレームワークです.
- chromadb: ベクトルデータを保存・検索するためのデータベースです.
- ollama: PythonからOllama(AIモデル)を操作するためのライブラリです.
- tqdm: 処理の進捗バーを表示するためのツールです.(表示用)
5. DBの作成 (コードの実行)
以下のコードを実行し,検索用DBを作成します.
LLMProcessor にラベル付けをさせ,VectorProcessorにベクトル化をさせる2段階で行っています.
ぜひ,検証用コードフォルダに自分で書いたコードも何個か混ぜてみてください.
※ CPUを使用する場合は USE_LLM = Falseに設定し, VectorProcessor の初期化部分の model_kwargs={"device": "cuda"} を model_kwargs={"device": "cpu"} に書き換えてください.
このコードを実行すると,フォルダ内に2つのデータベースが生成されます.
-
① file_management.db (SQLite)
進捗管理用のDBです.AIが生成した要約をここに一時保存します.
もし途中でPCが止まっても,次回は続きから再開できます. -
② chroma_db_store (ChromaDB)
検索用のベクトルDBです.
最終的に検索アプリが読み込むのはこのファイルです.
import os
import re
import json
import time
from datetime import datetime
from tqdm import tqdm
import ollama
import sqlite3
import hashlib
import nbformat
import requests
# --- ベクトルDB用ライブラリ ---
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
from langchain_core.documents import Document
from langchain_text_splitters import RecursiveCharacterTextSplitter
# ==========================================
# ⚙️ 設定エリア (LLM_MODELはスペックに応じて LLM_MODEL = "qwen2.5-coder:7b" のように変更してください)
# ==========================================
# CPUを使用する場合はここをFalseに変えてください 手順1のラベル付けをスキップします
USE_LLM = True
TARGET_ROOT_DIR = r"検証用コード"
DB_PERSIST_DIR = "chroma_db_store" # 検索用ベクトルDB
SQLITE_DB_PATH = "file_management.db" # 処理済みのファイルのDB
EMBEDDING_MODEL = "intfloat/multilingual-e5-large" # ベクトル化用の埋め込みモデル
LLM_MODEL = "qwen2.5-coder:14b" # 要約・キーワード生成用のモデル
MAX_CODE_CHARS_FOR_LLM = 15000 # 長すぎるコードは省略する
# このフォルダ名以下のファイルは無視する
EXCLUDE_DIR = ['.git', '__pycache__', 'node_modules', 'venv', '.ipynb_checkpoints']
# ==========================================
# ==========================================
# 1. データ管理クラス (SQLite担当)
# ==========================================
class DataManager:
# 進捗状況とメタデータをSQLiteで管理するクラス
def __init__(self):
self.conn = sqlite3.connect(SQLITE_DB_PATH)
self.create_table()
def create_table(self):
cursor = self.conn.cursor()
cursor.execute('''
CREATE TABLE IF NOT EXISTS file_status (
file_path TEXT PRIMARY KEY,
content_hash TEXT,
summary TEXT,
keywords TEXT,
last_processed_at TIMESTAMP,
status TEXT
)
''')
self.conn.commit()
def get_file_hash(self, content):
return hashlib.md5(content.encode('utf-8', errors='ignore')).hexdigest()
def check_status(self, file_path, current_hash):
# ファイルの処理状態を確認
cursor = self.conn.cursor()
cursor.execute('SELECT content_hash, status FROM file_status WHERE file_path = ?', (file_path,))
row = cursor.fetchone()
if row is None: return "new"
stored_hash, status = row
if stored_hash != current_hash: return "modified"
return status
def update_record(self, file_path, content_hash, summary, keywords, status):
cursor = self.conn.cursor()
cursor.execute('''
INSERT OR REPLACE INTO file_status (file_path, content_hash, summary, keywords, last_processed_at, status)
VALUES (?, ?, ?, ?, ?, ?)
''', (file_path, content_hash, summary, keywords, datetime.now(), status))
self.conn.commit()
def get_analyzed_records(self):
# Phase 1 完了(analyzed)のデータを取得
cursor = self.conn.cursor()
cursor.execute("SELECT file_path, summary, keywords FROM file_status WHERE status = 'analyzed'")
return cursor.fetchall()
# ==========================================
# 2. LLM処理クラス (Ollama担当)
# ==========================================
class LLMProcessor:
# Ollamaを使って要約とキーワードを生成するクラス
def __init__(self):
pass # OllamaはAPI経由なので初期化ロードは不要
# コードを解析して要約・キーワードのJSONを返す
def analyze(self, code_content, filename):
if len(code_content) > MAX_CODE_CHARS_FOR_LLM:
input_text = code_content[:MAX_CODE_CHARS_FOR_LLM//2] + "\n\n# ... [省略] ...\n\n" + code_content[-MAX_CODE_CHARS_FOR_LLM//2:]
else:
input_text = code_content
prompt = f"""
あなたはコードアーカイブを管理する「司書AI」です.
**あなたは開発者ではありません.コードの修正やレビューは一切行わないでください.**
【コンテキスト】
以下のテキストは,巨大なソフトウェアシステムの「断片(フラグメント)」です.
関数定義が欠けていたり,importが不足しているのは**仕様**です.エラーを探さないでください.
【タスク】
このファイルが日本の検索エンジンでヒットするように,日本語のメタデータを作成してください.
【出力フォーマット(厳守)】
必ず以下のJSON形式のみを出力すること.
{{
"summary": "コードが何をするものか,3行程度の日本語で具体的に要約.",
"keywords": "日本語のキーワードをカンマ区切りで5個以上 (例: スクレイピング, 貪欲法, ゲームAI)"
}}
--------------------------------------------------
**対象ファイル名**: {filename}
**コード断片**:
{input_text}
--------------------------------------------------
出力 (JSON):
"""
try:
response = ollama.chat(
model=LLM_MODEL,
format='json',
messages=[{'role': 'user', 'content': prompt}],
options={'temperature': 0.1} # 安定した回答が欲しいのでtemperatureを低めに設定します
)
return self._extract_json(response['message']['content'])
except Exception as e:
return None, None
def _extract_json(self, text):
try:
match = re.search(r'\{.*\}', text, re.DOTALL)
if match:
data = json.loads(match.group(0))
return data.get('summary', '要約なし'), data.get('keywords', 'キーワードなし')
return "JSON Error", "Error"
except:
return "JSON Error", "Error"
# !!! 重要: 使用後にOllamaのメモリを強制開放する
def release_memory(self):
try:
requests.post(
"http://localhost:11434/api/generate",
json={"model": LLM_MODEL, "keep_alive": 0}
)
print("LLM Memory Released.")
except Exception as e:
print(f"Memory release failed: {e}")
# ==========================================
# 3. ベクトル処理クラス (Chroma担当)
# ==========================================
# EmbeddingモデルをロードしてDB登録するクラス
class VectorProcessor:
def __init__(self):
print(f"Loading Embedding Model: {EMBEDDING_MODEL} ...")
# ここでEMBEDDING_MODELがロードされる
self.embeddings = HuggingFaceEmbeddings(
model_name=EMBEDDING_MODEL,
model_kwargs={"device": "cuda"}, # CPUを使用する場合: model_kwargs={"device": "cpu"},
encode_kwargs={"normalize_embeddings": True}
)
self.vectorstore = Chroma(
persist_directory=DB_PERSIST_DIR,
embedding_function=self.embeddings,
collection_name="python_code_collection"
)
self.text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=200)
# ドキュメントを作成して登録
def register(self, file_path, summary, keywords, content):
filename = os.path.basename(file_path)
full_text = f"""
[FILE_NAME] {filename}
[PATH] {file_path}
[SUMMARY] {summary}
[KEYWORDS] {keywords}
[SOURCE_CODE]
{content}
"""
docs = self.text_splitter.create_documents(
[full_text],
metadatas=[{"source": file_path, "summary": summary, "keywords":keywords}]
)
# ベクトル化して保存
self.vectorstore.add_documents(docs)
# ==========================================
# ヘルパー関数
# ==========================================
# .py .ipynbを読み込む (.ipynbはコード部分だけ読み込む)
def load_file_content(file_path):
ext = os.path.splitext(file_path)[1].lower()
try:
if ext == '.ipynb':
with open(file_path, 'r', encoding='utf-8') as f:
nb = nbformat.read(f, as_version=4)
return "\n\n".join([c.source for c in nb.cells if c.cell_type == 'code'])
elif ext == '.py':
with open(file_path, 'r', encoding='utf-8') as f:
return f.read()
except:
return None
# ==========================================
# メイン処理
# ==========================================
def main():
# 1. ファイルリスト作成
db = DataManager()
target_files = []
print("Scanning files...")
for root, dirs, files in os.walk(TARGET_ROOT_DIR):
dirs[:] = [d for d in dirs if d not in EXLUDE_DIR]
for file in files:
if file.endswith(('.py', '.ipynb')):
target_files.append(os.path.join(root, file))
print(f"Found {len(target_files)} files.")
# ------------------------------------------
# 手順1: LLMによる要約とキーワードの生成
# ------------------------------------------
if USE_LLM:
print("\n--- Phase 1: AI Analysis ---")
llm = LLMProcessor() # LLM処理クラス の インスタンス化
pbar1 = tqdm(target_files, desc="LLM Processing") # 進捗バー
for file_path in pbar1:
content = load_file_content(file_path)
if not content: continue
current_hash = db.get_file_hash(content)
status = db.check_status(file_path, current_hash)
# 処理済みならスキップ
if status in ['completed', 'analyzed']:
continue
# LLM実行
filename = os.path.basename(file_path)
pbar1.set_postfix_str(f"Analyzing: {filename[:10]}...")
# 要約とキーワードを生成させる
summary, keywords = llm.analyze(content, filename)
if summary:
db.update_record(file_path, current_hash, summary, keywords, 'analyzed')
else:
db.update_record(file_path, "error", "LLM Failed", "", 'error')
# ★ 手順1 終了.ここでGPU専用メモリを空ける
llm.release_memory()
del llm # Pythonオブジェクトとしても消去
# ===========================================
else:
print("\n--- Phase 1: Skip ---")
pbar1 = tqdm(target_files, desc="Skipping LLM") # 進捗バー
for file_path in pbar1:
content = load_file_content(file_path)
if not content: continue
current_hash = db.get_file_hash(content)
status = db.check_status(file_path, current_hash)
if status in ['completed', 'analyzed']:
continue
# status を analyzed にしておく
db.update_record(file_path, current_hash, "", "", 'analyzed')
# ------------------------------------------
# 手順2: ベクトル化
# ------------------------------------------
print("\n--- Phase 2: Vectorizing ---")
records = db.get_analyzed_records()
if not records:
print("No new files to vectorize.")
return
# ベクトル化用の埋め込みモデルをロード
vectorizer = VectorProcessor()
pbar2 = tqdm(records, desc="Vectorizing")
for file_path, summary, keywords in pbar2:
content = load_file_content(file_path)
if not content: continue
try:
vectorizer.register(file_path, summary, keywords, content)
# 完了ステータスに更新
current_hash = db.get_file_hash(content)
db.update_record(file_path, current_hash, summary, keywords, 'completed')
except Exception as e:
print(f"Error: {e}")
print("\n✅ All Done!")
if __name__ == "__main__":
main()
6. 検索機能を試す
作成したベクトルDB(chroma_db_store)を使ってコードの検索をしてみます. 画像のように表示されれば成功です. アナグラムや音声解析などの明確な意図のあるコードであればタイトルまで匿名化したEXでも上位に表示されるはずです.



import os
import time
from langchain_chroma import Chroma
from langchain_huggingface import HuggingFaceEmbeddings
# ==========================================
# ⚙️ 設定 (DB作成用コード と合わせてください)
# ==========================================
DB_PERSIST_DIR = "chroma_db_store"
EMBEDDING_MODEL = "intfloat/multilingual-e5-large"
# ==========================================
def main():
print("Loading Search Engine... (This may take a moment)")
# 1. DB読み込み
embeddings = HuggingFaceEmbeddings(
model_name=EMBEDDING_MODEL,
model_kwargs={"device": "cuda"}, # CPUの場合は model_kwargs={"device": "cuda"},
encode_kwargs={"normalize_embeddings": True}
)
vectorstore = Chroma(
persist_directory=DB_PERSIST_DIR,
embedding_function=embeddings,
collection_name="python_code_collection"
)
print("\n Search Engine Ready!")
print("-" * 50)
while True:
query = input("\n 検索ワードを入力 (qで終了): ").strip()
if query.lower() == 'q':
break
if not query:
continue
start_time = time.time()
# 検索実行 (Top 5) (全部表示したい場合はkを大きくしてください)
# k=5 で上位5件を取得
k = 5
# チャンクサイズの関係で重複が起きるので多めに取得しておく
results = vectorstore.similarity_search_with_score(query, k=20)
duration = time.time() - start_time
print(f"\n--- Top 5 Results ({duration:.3f}s) ---")
seen_path = set()
cnt = 1
for (doc, score) in results:
# メタデータ取得
file_path = doc.metadata.get("source", "Unknown Path")
summary = doc.metadata.get("summary", "No Summary")
keywords = doc.metadata.get("keywords", "No Keywords")
if file_path not in seen_path:
# スコア表示 (E5系は距離なので、低いほど近い...はずですが、ライブラリによって正規化されます)
print(f"[{cnt}] Path: {os.path.basename(file_path)}, SCORE:{score}")
print(f" Full: {file_path}")
print(f" AI Summary: {summary[:100]}") # AIによる要約
print(f" AI Keywords: {keywords}") # AIによるキーワード
print("-" * 20)
seen_path.add(file_path)
cnt += 1
if __name__ == "__main__":
main()
7. 検証 本当にラベル付けは必要か?
実はラベル付けがなくてもHardまでならファイル名を頼りにベクトル化だけでもある程度,検索ができてしまいます.
作成済みのDBを削除して 5. DBの作成 (コードの実行) のコードを USE_LLM = False にして実行すると,LLMによるラベル付けなしでDBを作成できます.
コメントが綺麗に書き込まれたコードや分かりやすい変数名 ファイル名が付けられているコードであれば,ベクトル化のみでもそこそこの精度が出ますが,Untitled, test, a_v1などのファイル名で適当に書いたファイルを探したい場合はLLMによるラベル付けがないとベクトル化だけでは探し出すことができません.
実際,私も最初はベクトル化だけで試したのですが,untitled やら testやら酷いファイル名に酷いコードが散らかりまくってるせいでラベル付け無しでは使い物になりませんでした...


8. まとめと応用
今回はローカル環境で大規模言語モデルと埋め込みモデルを動かしてAIストレージ内検索を実装しました. 今回はコードであったため,LLMによるラベル付けがないと曖昧なファイルの検索ができませんでしたが,これが最初から明確な文脈を持つメールやツイートであれば,文中で使われていた正確な文言を思い出せなくても(比較的軽い)ベクトル化だけで今回の検索システムを実装することができます. また,画像や音声データもラベル付けに使用するモデルをVLM(Vision-Language-Model)やALM(Audio-Language Model)に差し替えることで同じような検索システムが実装できます.