今回はリアルタイムでの音階判定について説明していきます.
早速ですが,音階をリアルタイムで判定するプログラムです. マイクが使える環境で走らせるとピークの周波数と音名が表示されます.
import pyaudio
import numpy as np
# 周波数を音名に直す関数
def frequency_to_pitch(frequency):
A4 = 440.0 # 基準音 A4 = 440.0Hz
C0 = A4 * (2**(-57/12)) # A4からn個離れている場合は A4*(2**(n/12))
# 周波数が0であれば音階無し
if frequency == 0:
return None
h = 12 * np.log2(frequency / C0) # C0からの半音単位での距離を計算
h_rounded = round(h) # 四捨五入して最も近い半音に合わせる
octave = h_rounded // 12 # オクターブの計算
n = h_rounded % 12 # 音名のインデックスの計算
pitch_names = ['C', 'C#', 'D', 'D#', 'E', 'F', 'F#', 'G', 'G#', 'A', 'A#', 'B']
pitch = pitch_names[n] + str(octave)
return pitch
# マイクから音声を取得し音名を表示し続ける(無限ループ)
def run():
FORMAT = pyaudio.paInt16 # 16ビットのオーディオフォーマットを指定
CHANNELS = 1 # モノラルで録音
RATE = 44100 # マイクのサンプリングレート 1秒間に何個のデータを受け取るか
CHUNK = 8192 # チャンクサイズ 8192個のデータが溜まったら音階判定を行う
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
while True:
data = stream.read(CHUNK) # チャンクサイズ分のデータを読み取る ここでは8192
samples = np.frombuffer(data, dtype=np.int16)
fft_result = np.fft.fft(samples) # FFTを用いて周波数成分に変換
frequencies = np.fft.fftfreq(len(fft_result)) # 周波数の配列を取得
# 最大振幅の周波数を取得
peak_freq = abs(frequencies[np.argmax(np.abs(fft_result))] * RATE)
# 周波数を音名に変換
pitch = frequency_to_pitch(peak_freq)
print(f"ピーク: {peak_freq:.2f}Hz, 音名:{pitch}")
run()
frequency_to_pitchの内容を理解するためには,「そもそも音名(A4など)が何なのか」を理解する必要があります.
丸投げをするなら以下のような参考になるサイトがいくつかあります.
【参考(外部サイト)】① 音名と階名 -Wikipedia
【参考(外部サイト)】② オクターヴ -Wikipedia
【参考(外部サイト)】③ 音階の周波数 -tomariのホームページ
【参考(外部サイト)】④ 12平均律と周波数
③,④のサイトに各音の周波数と計算方法が書いてあります.
「12平均律」または「等間隔音律」と呼ばれると呼ばれる調律法に基づいて隣接する音の周波数比が一定の比率になるように定めていきます.
具体的には以下の2つの要請を満たす必要があります.
A4 = 440.0 # 基準音 A4 = 440.0Hz
C0 = A4 * (2**(-57/12)) # A4からn個離れている場合は A4*(2**(n/12))
h = 12 * np.log2(frequency / C0) # C0からの半音単位での距離を計算
h_rounded = round(h) # 四捨五入して最も近い半音に合わせる
octave = h_rounded // 12 # オクターブの計算
n = h_rounded % 12 # 音名のインデックスの計算
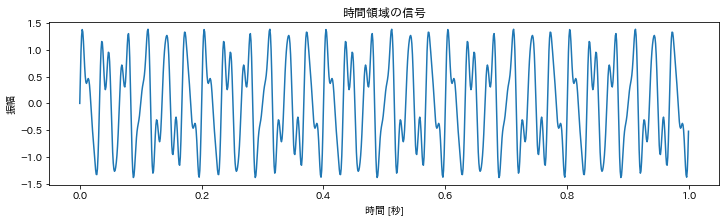
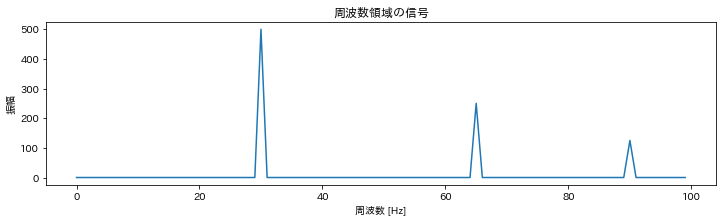
周波数を音名とオクターブに変換する方法は分かりました. ですが,いま鳴っている音の周波数が何Hzか分からないことには音名が分かりません. 以下のコードのpeak_freq(一番大きく鳴っている音の周波数)を求める必要があります.(厳密にはこれではオクターブまで正しく判定はできないのですが,これは後で解説します) 詳しい計算方法については触れませんが,FFT(Fast Fourier Transformation:高速フーリエ変換)を使って(1)時間領域の信号(音の波)を (2)周波数領域の信号に変換します. 以下の画像の場合は30Hzの音が一番大きく鳴っているのでpreak_frekは30Hzです.
data = stream.read(CHUNK) # チャンクサイズ分のデータを読み取る ここでは8192
samples = np.frombuffer(data, dtype=np.int16)
fft_result = np.fft.fft(samples) # FFTを用いて周波数成分に変換
frequencies = np.fft.fftfreq(len(fft_result)) # 周波数の配列を取得
# 最大振幅の周波数を取得(どの周波数の音が一番大きく鳴っているか)
peak_freq = abs(frequencies[np.argmax(np.abs(fft_result))] * RATE)
# 周波数を音名に変換
pitch = frequency_to_pitch(peak_freq)
何Hz刻みで周波数が判定できるかを周波数分解能,何秒刻みで周波数が判定できるかを時間分解能と言います.
例えば,0.1秒ごとに2Hz刻みで音を判定できるならば,周波数分解能は2Hz,時間分解能は0.1秒です.
リアルタイムの音程判定において周波数分解能と時間分解能は以下のようなトレードオフの関係にあります.
時間分解能 = CHUNK / RATE
周波数分解能 = RATE / CHUNK
※ RATE:マイクのサンプリングレート, CHUNK:判定に使うデータの塊の長さ(サンプリング点数)
サンプリングレート:44100Hz, チャンクサイズ:8192の場合は時間分解能は0.186秒 周波数分解能は5.38Hzです.
時間窓長とサンプリング点数との関係は? -小野測器
周波数分解能はどのように決めるのか? -小野測器
実際にリアルタイムの音程解析を試してみると,低音の判定が思うよりも上手くいかないように感じるかもしれません. 以下の表は音と周波数の対応表です. サンプリングレートを44100Hz, チャンクサイズを8192としたときに判定できない音は赤くしてあります. 周波数分解能が約5.38Hzなので16.15Hz(≒C0)の次が21.53Hz(≒F0)となってしまうため間の音は正確に判定できません. 周波数で見ると低音は前後の音との間隔が小さいため判定することができない音が出てきてしまいます. 今回の例ではE2が正確に判定できる限界の低さです.
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|
自己相関関数を使用した基本周波数の測定 -TadaoYamaokaの開発日記で紹介されている方法で倍音の誤検出が防げるようです. run()を最も強くなっている音ではなく一番左のピークを取るように以下のように書き換えました.
# マイクから音声を取得し音名を表示し続ける(無限ループ)
def run():
FORMAT = pyaudio.paInt16 # 16ビットのオーディオフォーマットを指定
CHANNELS = 1 # モノラルで録音
RATE = 44100 # マイクのサンプリングレート 1秒間に何個のデータを受け取るか
CHUNK = 8192 # チャンクサイズ 8192個のデータが溜まったら音階判定を行う
audio = pyaudio.PyAudio()
stream = audio.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
while True:
data = stream.read(CHUNK) # チャンクサイズ分のデータを読み取る ここでは8192
samples = np.frombuffer(data, dtype=np.int16)
fft_result = np.fft.fft(samples) # FFTを用いて周波数成分に変換
# https://tadaoyamaoka.hatenablog.com/entry/2016/08/28/114423 (自己相関関数を使用した基本周波数の測定)
acf = np.fft.ifft(abs(fft_result)**2)
n = pick_peak(acf[0:CHUNK//2])
peak_freq = RATE/n
# 周波数を音名に変換
pitch = frequency_to_pitch(peak_freq)
print(f"ピーク: {peak_freq:.2f}Hz, 音名:{pitch}")