今回は棋譜を訓練データとして次の一手を予想する方策ネットワークを作ります. 以下の手順で進めます.こちらの8×8のAIの強さ程度のものが出来上がります. 全体の所要時間はGeForce RTX 2080を利用して2時間程度です.
ネット上で公開されているオセロの棋譜をダウンロードします.
ダウンロードしたデータはバイナリファイルであるためそのまま利用することができないので加工をします.
棋譜データをモデルの入力に使える形に加工します. 具体的には黒 白に対して8×8の配列をそれぞれ用意し,石の置いている場所を1 置いていない場所を0とする(2,8,8)の配列に加工します.
13層の畳み込みニューラルネットワーク(CNN)により方策ネットワークの学習を行います.
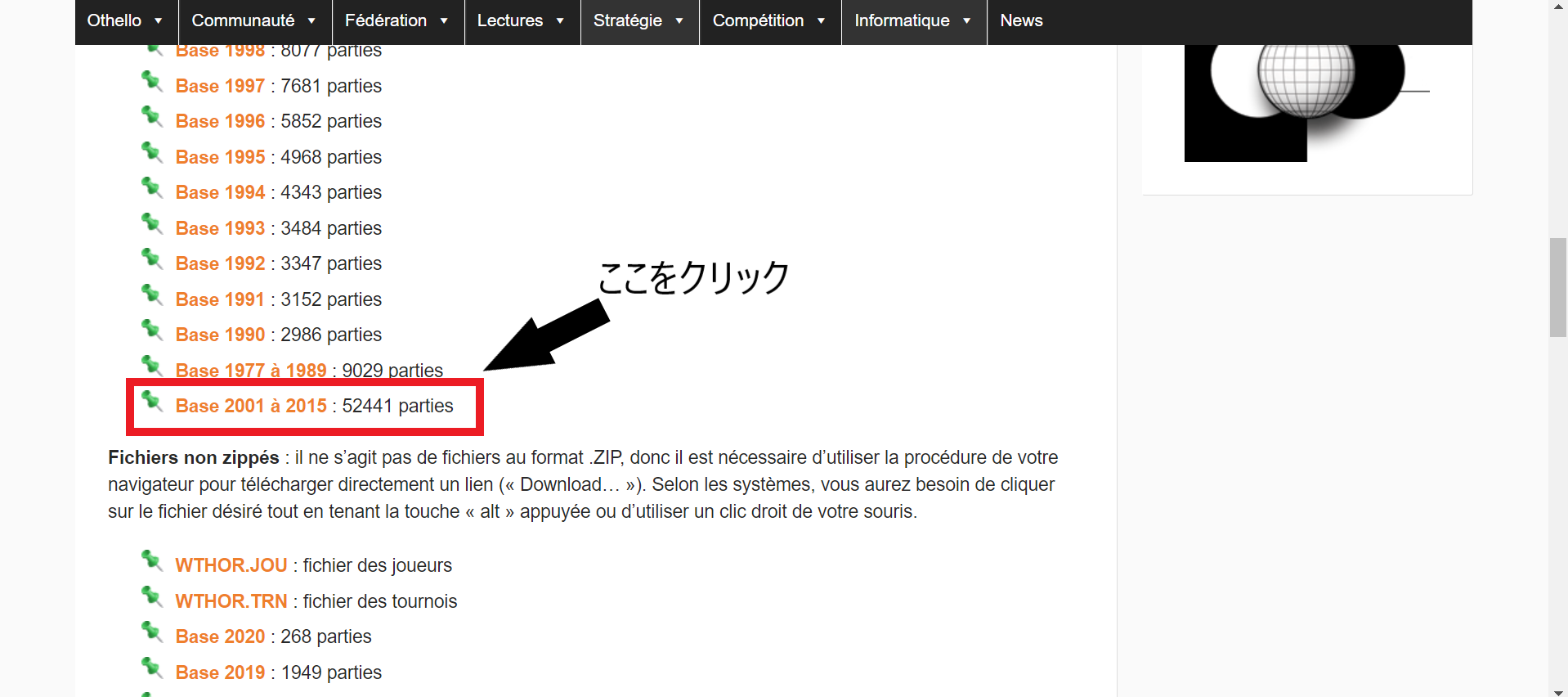
訓練データとして利用するための棋譜をダウンロードします.フランスオセロ連盟 のサイトを開き2001年から2015年までの52441局分のデータをダウンロードします.
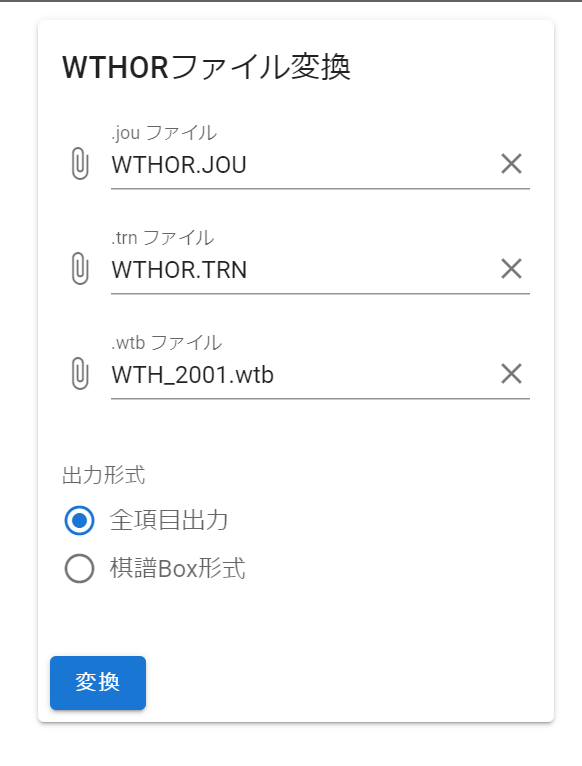
ダウンロードした棋譜データはバイナリデータであるため,これを加工します. 加工にはこちらの変換用サイトを利用します. また,棋譜データの詳しい中身については変換用サイトを作られた方がこちらのサイトで詳しく解説されています. 下の画像のようにjouファイル trnファイル wtbファイルを選択したあと「変換」をクリックします.
ここからはPythonを使って棋譜を加工しますが,少し長いです.
(1),(2),(3)がすべき作業の説明で,それ以外はファイルの内容や処理の内容の説明なので,分かりそうな方は読み飛ばしていただいて構いません.
変換したcsvファイルを見ると棋譜に加えて大会名や対局者の名前が含まれています.
今回,学習に利用したいのは局面の画像とプレイヤーの打った手だけなのでこのcsvファイルをさらに加工して,(2,8,8)の局面の画像とそれに対する正解データ(打った手)を作ります.
こちらの解説サイトによると「棋譜は1手目がF5になるように規格化されています」と書いてあり,実際のファイルを確認してみると「f5」から始まる
アルファベットと数字の羅列があることが確認できます.
これがオセロの棋譜です.
(1) 以下のコードで棋譜だけを取り出します.
「wthor_csv」フォルダと同じディレクトリで走らせてください.(もしくはファイル名の部分を適宜書き換えてください)
game_results = []
for i in range(15):
with open(f"wthor_csv/wthor{2001+i}.csv", 'rb') as f:
b = f.read()
results = str(b).split(",")
for result in results:
if result[0:2] == "f5":
game_results.append(result)
print(len(game_results))
f = open('game_record.txt', 'w')
for x in game_results:
f.write(str(x) + "\n")
f.close()
'''
TensorFlowによる深層強化学習入門 牧野浩二・西崎博光
リバーシプログラムを一部書き換え
'''
import tensorflow as tf
from tensorflow import keras
from tf_agents.environments import gym_wrapper, py_environment, tf_py_environment
from tf_agents.agents.dqn import dqn_agent
from tf_agents.networks import network
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.policies import policy_saver
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory, policy_step as ps
from tf_agents.specs import array_spec
from tf_agents.utils import common, nest_utils
import numpy as np
import random
import copy
import datetime
SIZE = 8 # 盤面のサイズ SIZE*SIZE
NONE = 0 # 盤面のある座標にある石:なし
BLACK = 1# 盤面のある座標にある石:黒
WHITE = 2# 盤面のある座標にある石:白
STONE = {NONE:" ", BLACK:"●", WHITE:"○"}# 石の表示用
ROWLABEL = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7, 'h':8} #ボードの横軸ラベル
N2L = ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'] # 横軸ラベルの逆引き用
REWARD_WIN = 1 # 勝ったときの報酬
REWARD_LOSE = -1 # 負けたときの報酬
# 2次元のボード上での隣接8方向の定義(左から,上,右上,右,右下,下,左下,左,左上)
DIR = ((-1,0), (-1,1), (0,1), (1,1), (1,0), (1, -1), (0,-1), (-1,-1))
#シミュレータークラス
class Board(py_environment.PyEnvironment):
def __init__(self):
super(Board, self).__init__()
self._observation_spec = array_spec.BoundedArraySpec(
shape=(SIZE,SIZE,1), dtype=np.float32, minimum=0, maximum=2
)
self._action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=SIZE*SIZE-1
)
self.reset()
def observation_spec(self):
return self._observation_spec
def action_spec(self):
return self._action_spec
#ボードの初期化
def _reset(self):
self.board = np.zeros((SIZE, SIZE, 1), dtype=np.float32) # 全ての石をクリア.ボードは2次元配列(i, j)で定義する.
mid = SIZE // 2 # 真ん中の基準ポジション
# 初期4つの石を配置
self.board[mid, mid] = WHITE
self.board[mid-1, mid-1] = WHITE
self.board[mid-1, mid] = BLACK
self.board[mid, mid-1] = BLACK
self.winner = NONE # 勝者
self.turn = BLACK
self.game_end = False # ゲーム終了チェックフラグ
self.pss = 0 # パスチェック用フラグ.双方がパスをするとゲーム終了
self.nofb = 0 # ボード上の黒石の数
self.nofw = 0 # ボード上の白石の数
self.available_pos = self.search_positions() # self.turnの石が置ける場所のリスト
time_step = ts.restart(self.board)
return nest_utils.batch_nested_array(time_step)
#行動による状態変化(石を置く&リバース処理)
def _step(self, pos):
pos = nest_utils.unbatch_nested_array(pos)
pos = divmod(pos, SIZE)
if self.is_available(pos):
self.board[pos[0], pos[1]] = self.turn
self.do_reverse(pos) # リバース
self.end_check()#終了したかチェック
time_step = ts.transition(self.board, reward=0, discount=1)
return nest_utils.batch_nested_array(time_step)
#ターンチェンジ
def change_turn(self, role=None):
if role is NONE:
role = random.choice([WHITE,BLACK])
if role is None or role != self.turn:
self.turn = WHITE if self.turn == BLACK else BLACK
self.available_pos = self.search_positions() # 石が置ける場所を探索しておく
#ランダムに石を置く場所を決める(ε-greedy用)
def random_action(self):
if len(self.available_pos) > 0:
pos = random.choice(self.available_pos) # 置く場所をランダムに決める
pos = pos[0] * SIZE + pos[1] # 1次元座標に変換(NNの教師データは1次元でないといけない)
return pos
return False # 置く場所なし
#リバース処理
def do_reverse(self, pos):
for di, dj in DIR:
opp = BLACK if self.turn == WHITE else WHITE # 対戦相手の石
boardcopy = self.board.copy() # 一旦ボードをコピーする(copyを使わないと参照渡しになるので注意)
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and boardcopy[i,j] == opp: # 盤面に収まっており,かつ相手の石だったら
flag = True
boardcopy[i,j] = self.turn # 自分の石にひっくり返す
# 元のやつは or self.board[i,j] == NONE が抜けている
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and boardcopy[i,j] != opp) or self.board[i,j] == NONE:
break
elif boardcopy[i,j] == self.turn and flag == True: # 自分と同じ色の石がくれば挟んでいるのでリバース処理を確定
self.board = boardcopy.copy() # ボードを更新
break
#石が置ける場所をリストアップする.石が置ける場所がなければ「パス」となる
def search_positions(self):
pos = []
emp = np.where(self.board == 0) # 石が置かれていない場所を取得
for i in range(emp[0].size): # 石が置かれていない全ての座標に対して
p = (emp[0][i], emp[1][i]) # (i,j)座標に変換
if self.is_available(p):
pos.append(p) # 石が置ける場所の座標リストの生成
return pos
#石が置けるかをチェックする
def is_available(self, pos):
if self.board[pos[0], pos[1]] != NONE: # 既に石が置いてあれば,置けない
return False
opp = BLACK if self.turn == WHITE else WHITE
for di, dj in DIR: # 8方向の挟み(リバースできるか)チェック
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and self.board[i,j] == opp: #盤面に収まっており,かつ相手の石だったら
flag = True
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and self.board[i,j] != opp) or self.board[i,j] == NONE:
break
elif self.board[i,j] == self.turn and flag == True: # 自分と同じ色の石
return True
return False
#ゲーム終了チェック
def end_check(self):
if np.count_nonzero(self.board) == SIZE * SIZE or self.pss == 2: # ボードに全て石が埋まるか,双方がパスがしたら
self.game_end = True
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
self.winner = NONE
#パスしたときの処理
def add_pass(self):
self.pss += 1
#パスした後の処理
def clear_pass(self):
self.pss = 0
def convert_move(str_move):
str_dict = {"a":0, "b":1, "c":2, "d":3, "e":4, "f":5, "g":6, "h":7}
move = str_dict[str_move[0]] + 8*(int(str_move[1])-1)
return move
def make_train_data(num,parallel_num,game_num=52441):
# データの読み込み
f = open("game_record.txt","r")
list_row = []
list_length = game_num//parallel_num + 1
start_idx = num*(list_length)
end_idx = min(num*(list_length)+list_length,game_num)
cnt = 0
for x in f:
if end_idx >= cnt >= start_idx:
list_row.append(x.rstrip("\n"))
if len(list_row) >= list_length:
break
cnt += 1
f.close()
############################# 棋譜の作成 ################################
#環境の設定
env_py = Board()
target = {"WIN":[],"LOSE":[],"DRAW":[]}
images = {"WIN":[],"LOSE":[],"DRAW":[]}
game_count = 0
progress = 0
if num == 0:
print(f"{datetime.datetime.now()}: done {0}/{len(list_row)}")
for moves in list_row:
game_count += 1
progress += 1
if num==0 and len(list_row)//100 <= game_count:
game_count = 0
print(f"{datetime.datetime.now()}: done {progress}/{len(list_row)}")
env_py.reset()
turn = 0
sub_target = {WHITE:[],BLACK:[]}
sub_images = {WHITE:[],BLACK:[]}
while not env_py.game_end: # ゲームが終わるまで繰り返す
if not env_py.available_pos:# 石が置けない場合はパス
env_py.add_pass()
env_py.end_check()
else:# 石を置く処理
move = moves[turn*2:turn*2+2]
move = convert_move(move)
pos = divmod(move, SIZE) # 座標を2次元(i,j)に変換
turn += 1
sub_target[env_py.turn].append(move)
image = np.zeros((2,8,8))
if env_py.turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
# 自分の手番が前に来るようにした
image[0] = copy.deepcopy(np.array(env_py.board.reshape((8,8))==env_py.turn,"float32"))
image[1] = copy.deepcopy(np.array(env_py.board.reshape((8,8))==enemy_turn,"float32"))
sub_images[env_py.turn].append(copy.deepcopy(image))
env_py.step(move)# 石を配置
env_py.clear_pass() # 石が配置できた場合にはパスフラグをリセットしておく(双方が連続パスするとゲーム終了する)
if env_py.game_end:#ゲーム終了時の処理
if env_py.winner == BLACK:
target["WIN"] = target["WIN"] + copy.deepcopy(sub_target[BLACK])
images["WIN"] = images["WIN"] + copy.deepcopy(sub_images[BLACK])
target["LOSE"] = target["LOSE"] + copy.deepcopy(sub_target[WHITE])
images["LOSE"] = images["LOSE"] + copy.deepcopy(sub_images[WHITE])
elif env_py.winner == WHITE:
target["WIN"] = target["WIN"] + copy.deepcopy(sub_target[WHITE])
images["WIN"] = images["WIN"] + copy.deepcopy(sub_images[WHITE])
target["LOSE"] = target["LOSE"] + copy.deepcopy(sub_target[BLACK])
images["LOSE"] = images["LOSE"] + copy.deepcopy(sub_images[BLACK])
else:
target["DRAW"] = target["DRAW"] + copy.deepcopy(sub_target[WHITE])
images["DRAW"] = images["DRAW"] + copy.deepcopy(sub_images[WHITE])
target["DRAW"] = target["DRAW"] + copy.deepcopy(sub_target[BLACK])
images["DRAW"] = images["DRAW"] + copy.deepcopy(sub_images[BLACK])
else:
env_py.change_turn()
############# targetの保存 ########################
f = open(f'train_data/target_win/target_win{num}.txt', 'w')
for x in target["WIN"]:
f.write(str(x) + "\n")
f.close()
f = open(f'train_data/target_lose/target_lose{num}.txt', 'w')
for x in target["LOSE"]:
f.write(str(x) + "\n")
f.close()
f = open(f'train_data/target_draw/target_draw{num}.txt', 'w')
for x in target["DRAW"]:
f.write(str(x) + "\n")
f.close()
############## imageの保存 ########################
images_array = np.zeros((len(images["WIN"]),2,8,8))
idx = 0
for image in images["WIN"]:
images_array[idx] = image
idx += 1
np.save(f"train_data/image_win/image_win{num}.npy",images_array)
images_array = np.zeros((len(images["LOSE"]),2,8,8))
idx = 0
for image in images["LOSE"]:
images_array[idx] = image
idx += 1
np.save(f"train_data/image_lose/image_lose{num}.npy",images_array)
images_array = np.zeros((len(images["DRAW"]),2,8,8))
idx = 0
for image in images["DRAW"]:
images_array[idx] = image
idx += 1
np.save(f"train_data/image_draw/image_draw{num}.npy",images_array)
print(f"{datetime.datetime.now()}: 変換終了.")
from multiprocessing import Process
from make_train_data import make_train_data
import numpy as np
import copy
import os
os.mkdir("train_data")
folder_names = ["target_win","target_draw","target_lose","image_win","image_draw","image_lose"]
for folder_name in folder_names:
os.mkdir(f"train_data/{folder_name}")
### 並列処理を行いたくない場合はこの部分をコメントアウト ###
process_list = []
parallel_num = 16 # 並列処理のスレッド数
for i in range(parallel_num):
process = Process(
target=make_train_data,
kwargs={'num':i,"parallel_num":parallel_num})
process.start()
process_list.append(process)
for process in process_list:
process.join()
###########################################################
# parallel_num = 1
# make_train_data(0,1) # 並列処理を行わない場合はこちら(非推奨)
file_names = ["target_lose/target_lose", "target_draw/target_draw", "target_win/target_win"]
target_policy = []
target_value = []
for i in range(parallel_num):
for file_name in file_names:
f = open(f"train_data/{file_name}{i}.txt","r")
if file_name == "target_lose/target_lose":
for x in f:
num = int(x.strip("\n"))
target_policy.append(num)
target_value.append(0)
elif file_name == "target_draw/target_draw":
for x in f:
num = int(x.strip("\n"))
target_policy.append(num)
target_value.append(0.5)
else:
for x in f:
num = int(x.strip("\n"))
target_policy.append(num)
target_value.append(1)
f.close()
file_names = ["image_lose/image_lose","image_draw/image_draw","image_win/image_win"]
image = np.zeros((len(target_policy),2,8,8))
idx = 0
for i in range(parallel_num):
for file_name in file_names:
images = np.load(f"train_data/{file_name}{i}.npy")
image[idx:idx+images.shape[0]] = copy.deepcopy(images)
idx += images.shape[0]
############# targetの保存 ########################
f = open(f'target_policy.txt', 'w')
for x in target_policy:
f.write(str(x) + "\n")
f.close()
f = open(f'target_value.txt', 'w')
for x in target_value:
f.write(str(x) + "\n")
f.close()
############## imageの保存 ########################
np.save(f"image.npy",image)
訓練データの準備ができたのでTensorFlowを使って方策ネットワークの学習を行います. 上でも説明したよう,入力は自分の色の石のある場所を1 それ以外を0とした画像を1枚目 相手の色の石のある場所を1 それ以外を0とした画像を2枚目とした(2,8,8)の画像です. 学習には13層の畳み込みニューラルネットワーク(CNN)を使用します. 出力層は「入力に対してプレイヤーがそれぞれの手を打つ確率」を返してほしいのでsoftmax関数を利用します. 今回は方策ネットワークの学習なので正解データにはtarget_policy.txtを使います. 以下のコードをtarget_policy.txt image.npyフォルダのあるディレクトリで走らせることで学習が始まります. 学習にはGeForce RTX 2080を利用して40分ほどかかります. 時間がかかりすぎる場合はepoch数を減らす batch_sizeを大きくするなど,メモリが足りなくなる場合は学習に使用するデータ数を減らすことで対応してください.
from sklearn.model_selection import train_test_split
import tensorflow as tf
import numpy as np
from tensorflow import keras
import os
import copy
from keras.callbacks import EarlyStopping
####### 正解データの読み込み ########
target = []
f = open("target_policy.txt","r")
for x in f:
num = int(x.rstrip("\n"))
target.append(num)
f.close()
target = np.array(target)
print("target loaded")
######################################
######### 画像データの読み込み #######
image = np.zeros((len(target),2,8,8))
idx = 0
img = np.load("image.npy")
image[idx:img.shape[0]+idx] = np.array(img,"float32")
idx += img.shape[0]
print("images loaded")
########################################
x_train, x_test, y_train, y_test = train_test_split(image,target) # validation用にデータを分割
print("data splited")
# 学習に使用するモデルの記述
model = keras.Sequential(
[
keras.layers.Permute((2,3,1), input_shape=(2,8,8)),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(128, kernel_size=3,padding='same',activation='relu'),
keras.layers.Conv2D(1, kernel_size=1,use_bias=True),
keras.layers.Flatten(),
keras.layers.Dense(64, activation='softmax')
]
)
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
print("model compiled")
x_train = tf.reshape(x_train, [-1, 2, 8, 8])
# EaelyStoppingの設定
early_stopping = EarlyStopping(
monitor='val_loss',
min_delta=0.0,
patience=2,
)
print("start train")
# 学習させる
history = model.fit(
x_train,
y_train,
epochs=30,
batch_size=1024,
validation_data=[x_test, y_test],
callbacks=[early_stopping] # CallBacksに設定
)
# 学習が終わったらモデルを保存する
model.save('Policy_network')
どのくらいの強さになったのか実際にプレイしてみて確かめます. こちらのコードで作ったモデルと対戦することができます. オセロ盤はpygameで描画しています.
import os
import numpy as np
import random
import copy
import datetime
import tensorflow as tf
from tensorflow import keras
import pygame
from pygame.locals import QUIT,KEYDOWN,K_LEFT,K_RIGHT,K_DOWN,K_UP,Rect,MOUSEBUTTONDOWN
MODEL = keras.models.load_model("Policy_network")
'''
TensorFlowによる深層強化学習入門 牧野浩二・西崎博光
リバーシプログラムを一部書き換え
'''
SIZE = 8 # 盤面のサイズ SIZE*SIZE
NONE = 0 # 盤面のある座標にある石:なし
BLACK = 1# 盤面のある座標にある石:黒
WHITE = 2# 盤面のある座標にある石:白
STONE = {NONE:" ", BLACK:"●", WHITE:"○"}# 石の表示用
ROWLABEL = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7, 'h':8} #ボードの横軸ラベル
N2L = ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'] # 横軸ラベルの逆引き用
REWARD_WIN = 1 # 勝ったときの報酬
REWARD_LOSE = -0.8 # 負けたときの報酬
# 2次元のボード上での隣接8方向の定義(左から,上,右上,右,右下,下,左下,左,左上)
DIR = ((-1,0), (-1,1), (0,1), (1,1), (1,0), (1, -1), (0,-1), (-1,-1))
#シミュレータークラス
class Othello():
def __init__(self):
self.reset()
#ボードの初期化
def reset(self):
self.board = np.zeros((SIZE, SIZE), dtype=np.float32) # 全ての石をクリア.ボードは2次元配列(i, j)で定義する.
mid = SIZE // 2 # 真ん中の基準ポジション
# 初期4つの石を配置
self.board[mid, mid] = WHITE
self.board[mid-1, mid-1] = WHITE
self.board[mid-1, mid] = BLACK
self.board[mid, mid-1] = BLACK
self.winner = NONE # 勝者
# self.turn = random.choice([BLACK,WHITE])
self.turn = 1
self.game_end = False # ゲーム終了チェックフラグ
self.pss = 0 # パスチェック用フラグ.双方がパスをするとゲーム終了
self.nofb = 0 # ボード上の黒石の数
self.nofw = 0 # ボード上の白石の数
self.available_pos = self.search_positions() # self.turnの石が置ける場所のリスト
return self.board
#行動による状態変化(石を置く&リバース処理)
def step(self, pos):
pos = divmod(pos, SIZE)
# 成功したかどうか
success = False
if self.is_available(pos):
self.board[pos[0], pos[1]] = self.turn
self.do_reverse(pos) # リバース
success = True
self.end_check()#終了したかチェック
return self.board, success
#ターンチェンジ
def change_turn(self, role=None):
if role is NONE:
role = random.choice([WHITE,BLACK])
if role is None or role != self.turn:
self.turn = WHITE if self.turn == BLACK else BLACK
self.available_pos = self.search_positions() # 石が置ける場所を探索しておく
#ランダムに石を置く場所を決める(ε-greedy用)
def random_action(self):
legall_list = self.legall_list()
if len(legall_list) > 0:
# pos = random.choice(self.available_pos) # 置く場所をランダムに決める
# pos = pos[0] * SIZE + pos[1] # 1次元座標に変換(NNの教師データは1次元でないといけない)
pos =random.choice(legall_list)
return pos
return False # 置く場所なし
#リバース処理
def do_reverse(self, pos):
for di, dj in DIR:
opp = BLACK if self.turn == WHITE else WHITE # 対戦相手の石
boardcopy = self.board.copy() # 一旦ボードをコピーする(copyを使わないと参照渡しになるので注意)
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and boardcopy[i,j] == opp: # 盤面に収まっており,かつ相手の石だったら
flag = True
boardcopy[i,j] = self.turn # 自分の石にひっくり返す
# 元のやつは or self.board[i,j] == NONE が抜けている
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and boardcopy[i,j] != opp) or self.board[i,j] == NONE:
break
elif boardcopy[i,j] == self.turn and flag == True: # 自分と同じ色の石がくれば挟んでいるのでリバース処理を確定
self.board = boardcopy.copy() # ボードを更新
break
#石が置ける場所をリストアップする.石が置ける場所がなければ「パス」となる
def search_positions(self):
pos = []
emp = np.where(self.board == 0) # 石が置かれていない場所を取得
for i in range(emp[0].size): # 石が置かれていない全ての座標に対して
p = (emp[0][i], emp[1][i]) # (i,j)座標に変換
if self.is_available(p):
pos.append(p) # 石が置ける場所の座標リストの生成
return pos
#石が置けるかをチェックする
def is_available(self, pos):
if self.board[pos[0], pos[1]] != NONE: # 既に石が置いてあれば,置けない
return False
opp = BLACK if self.turn == WHITE else WHITE
for di, dj in DIR: # 8方向の挟み(リバースできるか)チェック
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and self.board[i,j] == opp: #盤面に収まっており,かつ相手の石だったら
flag = True
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and self.board[i,j] != opp) or self.board[i,j] == NONE:
break
elif self.board[i,j] == self.turn and flag == True: # 自分と同じ色の石
return True
return False
#ゲーム終了チェック
def end_check(self):
if np.count_nonzero(self.board) == SIZE * SIZE or self.pss == 2: # ボードに全て石が埋まるか,双方がパスがしたら
self.game_end = True
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
self.winner = 3
# お互いが置けなければ終了
def end_check2(self):
legall_list1 = self.legall_list()
if len(legall_list1) != 0:
return 0
else:
if self.turn == 1:
self.turn = 2
else:
self.turn = 1
legall_list2 = self.legall_list()
if len(legall_list2) != 0:
return 0
return 1
def change_turn2(self):
if self.turn == 1:
self.turn = 2
else:
self.turn = 1
# 引き分けの時はNoneではなく3にする
def judge(self):
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
# 引き分けを3にした
self.winner = 3
return self.winner
def legall_list(self):
legall_list = []
for i in range(SIZE**2):
pos = divmod(i,SIZE)
is_legall = self.is_available(pos)
if is_legall:
legall_list.append(i)
return legall_list
#パスしたときの処理
def add_pass(self):
self.pss += 1
#パスした後の処理
def clear_pass(self):
self.pss = 0
# board to state_number
def board2state(board):
state_num = ""
for row in range(SIZE):
for col in range(SIZE):
state_num = state_num + str(int(board[row][col]))
return state_num
#ランダム行動を行うときのポリシー
def random_policy_step(random_action_function):
random_act = random_action_function()
if random_act is not False:
return random_act
else:
raise Exception("No position avaliable.")
# 左上から順に埋めていく
import matplotlib.pyplot as plt
def position_search(pos_x,pos_y):
return pos_y//50,pos_x//50
def play_othello():
my_turn = int(input("BLACK:1, WHITE:2"))
if my_turn == 1:
enemy_turn0 = 2
else:
enemy_turn0 = 1
pygame.init()
pygame.key.set_repeat(5,5)
width = 400
hight = 400
surface = pygame.display.set_mode((width,hight))
fpsclock = pygame.time.Clock()
env = Othello()
color = 1
fps = 10
myfont = pygame.font.SysFont(None, 40)
while True:
for event in pygame.event.get():
steped = False
if event.type == QUIT:
pygame.quit()
sys.exit()
elif True: # 自分のターンの処理
current_time_step = np.zeros((1,2,8,8))
# 自分の手番が前に来るようにする
if env.turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
current_time_step[0][0] = np.array(env.board==env.turn,"float32")
current_time_step[0][1] = np.array(env.board==enemy_turn,"float32")
if not env.legall_list():# 石が置けない場合はパス
env.add_pass()
env.end_check()
steped = True
else:# 石を置く処理
if env.turn == enemy_turn0:
print("###########")
steped = True
value = MODEL(current_time_step) #設定したランダムポリシー
value = np.array(value)
value_dict = {}
for move in env.legall_list():
value_dict[move] = value[0][move]
print(value_dict)
policy_step = np.argmax(value)
if not policy_step in env.legall_list():
policy_step = random_policy_step(env.random_action)
log = env.step(policy_step)# 石を配置
print(log[1])
else:
if event.type == MOUSEBUTTONDOWN:
value = MODEL(current_time_step) #設定したランダムポリシー
value = np.array(value)
value_dict = {}
for move in env.legall_list():
value_dict[move] = value[0][move]
print(value_dict)
pos_x,pos_y = event.pos
row,col = position_search(pos_x,pos_y)
# print(row*8+col,env.legall_list(),row*8+col in env.legall_list())
while True:
if row*8+col in env.legall_list():
policy_step = row*8+col
steped = True
env.step(policy_step)# 石を配置
break
else:
break
if steped:
print(env.turn,policy_step)
env.clear_pass() # 石が配置できた場合にはパスフラグをリセットしておく(双方が連続パスするとゲーム終了する)
if env.game_end:#ゲーム終了時の処理
result = env.judge()
print("result",result)
else:
# print(steped)
if steped:
env.change_turn()
surface.fill((0,255,20))
# 盤面の描画をする
for i in range(1,8):
pygame.draw.line(surface, (0,0,0), (0,i*50), (400,i*50), width=1)
pygame.draw.line(surface, (0,0,0), (i*50,0), (i*50,400), width=1)
# 石を描画する
for x in range(8):
for y in range(8):
if env.board[x][y] == 1:
pygame.draw.circle(surface, (0,0,0), (50*y+25,50*x+25), 18, width=0)
elif env.board[x][y] == 2:
pygame.draw.circle(surface, (255,255,255), (50*y+25,50*x+25), 18, width=0)
# 置けるところを描画する
if color == 2:
for i in range(len(valid_hand)):
pygame.draw.circle(surface, (0,0,255), (50*valid_hand[i][0]+25,50*valid_hand[i][1]+25), 5, width=0)
pygame.display.update()
fpsclock.tick(fps)
今回,学習させた方策ネットワークは訓練データ数を増やすことで多少強くすることができます. 2001年から2015年以外にもオセロの棋譜データがあるのでこれらをダウンロードすることで訓練データを増やせます. こちらで公開してる8×8のオセロAIは今回使った訓練データに加えて, 局面を(1)2回転する (2)転置する (3)転置したものを2回転する の3パターンを水増ししたものを学習しています. 次回は与えられた局面から対局した場合に勝つか負けるかを判断する価値ネットワークを学習させます.