今回は6×6のオセロをプレイするAIを作ります.
8×8のオセロや将棋,囲碁などはネット上から大量の棋譜を得ることができるため,棋譜から学習をすることができるのですが,6×6のオセロは学習データを得ることができません.
そこで今回は深層学習と強化学習アルゴリズムの融合である深層強化学習という手法を使ってAIを作ります.
こちらでプレイできる6×6のオセロ程度の強さのAIが出来上がります.
深層強化学習の実装にはTensorflow TF-Agentsを使用します.
TF-Agentsの公式ドキュメントはこちら.
この記事で使用するプログラムは『TensorFlowによる深層強化学習入門』のプログラム(フリーソフトウェア)を一部改変して利用しています.
大きな変更点に関しては以下の通りです.
改変個所について
深層強化学習 特にDQNの概要
今回はTF-Agentsを使うためtf_agentsをインポートします. インストールしていない場合はpipなどでtf_agentsをインストールする必要があります. 私の手元ではTensorFlow2.7.0 TF-Agents0.11.0で動作を確認しています.
import tensorflow as tf
from tensorflow import keras
from tf_agents.environments import gym_wrapper, py_environment, tf_py_environment
from tf_agents.agents.dqn import dqn_agent
from tf_agents.networks import network
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.policies import policy_saver
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory, policy_step as ps
from tf_agents.specs import array_spec
from tf_agents.utils import common, nest_utils
import numpy as np
import random
import copy
import matplotlib.pyplot as plt
import datetime
SIZE = 6 # 盤面のサイズ SIZE*SIZE
NONE = 0 # 盤面のある座標にある石:なし
BLACK = 1# 盤面のある座標にある石:黒
WHITE = 2# 盤面のある座標にある石:白
STONE = {NONE:" ", BLACK:"●", WHITE:"○"}# 石の表示用
ROWLABEL = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7, 'h':8} #ボードの横軸ラベル
N2L = ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'] # 横軸ラベルの逆引き用
REWARD_WIN = 1 # 勝ったときの報酬
REWARD_LOSE = -1 # 負けたときの報酬
# 2次元のボード上での隣接8方向の定義(左から,上,右上,右,右下,下,左下,左,左上)
DIR = ((-1,0), (-1,1), (0,1), (1,1), (1,0), (1, -1), (0,-1), (-1,-1))
#シミュレータークラス
class Board(py_environment.PyEnvironment):
def __init__(self):
super(Board, self).__init__()
self._observation_spec = array_spec.BoundedArraySpec(
shape=(SIZE,SIZE,1), dtype=np.float32, minimum=0, maximum=2
)
self._action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=SIZE*SIZE-1
)
self.reset()
def observation_spec(self):
return self._observation_spec
def action_spec(self):
return self._action_spec
#ボードの初期化
def _reset(self):
self.board = np.zeros((SIZE, SIZE, 1), dtype=np.float32) # 全ての石をクリア.ボードは2次元配列(i, j)で定義する.
mid = SIZE // 2 # 真ん中の基準ポジション
# 初期4つの石を配置
self.board[mid, mid] = WHITE
self.board[mid-1, mid-1] = WHITE
self.board[mid-1, mid] = BLACK
self.board[mid, mid-1] = BLACK
self.winner = NONE # 勝者
# self.turn = random.choice([BLACK,WHITE])
self.turn = 1
self.game_end = False # ゲーム終了チェックフラグ
self.pss = 0 # パスチェック用フラグ.双方がパスをするとゲーム終了
self.nofb = 0 # ボード上の黒石の数
self.nofw = 0 # ボード上の白石の数
self.available_pos = self.search_positions() # self.turnの石が置ける場所のリスト
image2 = np.zeros((SIZE,SIZE,1),"float32")
if self.turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
image2[self.board==self.turn] = 1
image2[self.board==enemy_turn] = 2
time_step = ts.restart(image2)
return nest_utils.batch_nested_array(time_step)
#行動による状態変化(石を置く&リバース処理)
def _step(self, pos):
pos = nest_utils.unbatch_nested_array(pos)
pos = divmod(pos, SIZE)
if self.is_available(pos):
self.board[pos[0], pos[1]] = self.turn
self.do_reverse(pos) # リバース
self.end_check()#終了したかチェック
time_step = self.next_env()
return nest_utils.batch_nested_array(time_step)
# 自分の手番の色を1 相手の色を2にして状態を返す
def next_env(self):
env_copy = Board()
if self.turn == 1:
env_copy.turn = 2
else:
env_copy.turn = 1
env_copy.board = copy.deepcopy(self.board)
legall_list = env_copy.legall_list()
image2 = np.zeros((SIZE,SIZE,1),"float32")
# 相手がパスする場合
if len(legall_list) > 0:
image2[self.board==self.turn] = 1
image2[self.board==env_copy.turn] = 2
# 相手がパスしない場合
else:
image2[self.board==self.turn] = 2
image2[self.board==env_copy.turn] = 1
return ts.transition(image2, reward=0, discount=1)
#ターンチェンジ
def change_turn(self, role=None):
if role is NONE:
role = random.choice([WHITE,BLACK])
if role is None or role != self.turn:
self.turn = WHITE if self.turn == BLACK else BLACK
self.available_pos = self.search_positions() # 石が置ける場所を探索しておく
#ランダムに石を置く場所を決める(ε-greedy用)
def random_action(self):
if len(self.available_pos) > 0:
pos = random.choice(self.available_pos) # 置く場所をランダムに決める
pos = pos[0] * SIZE + pos[1] # 1次元座標に変換(NNの教師データは1次元でないといけない)
return pos
return False # 置く場所なし
#リバース処理
def do_reverse(self, pos):
for di, dj in DIR:
opp = BLACK if self.turn == WHITE else WHITE # 対戦相手の石
boardcopy = self.board.copy() # 一旦ボードをコピーする(copyを使わないと参照渡しになるので注意)
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and boardcopy[i,j] == opp: # 盤面に収まっており,かつ相手の石だったら
flag = True
boardcopy[i,j] = self.turn # 自分の石にひっくり返す
# 元のやつは or self.board[i,j] == NONE が抜けている!!!!!
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and boardcopy[i,j] != opp) or self.board[i,j] == NONE:
break
elif boardcopy[i,j] == self.turn and flag == True: # 自分と同じ色の石がくれば挟んでいるのでリバース処理を確定
self.board = boardcopy.copy() # ボードを更新
break
#石が置ける場所をリストアップする.石が置ける場所がなければ「パス」となる
def search_positions(self):
pos = []
emp = np.where(self.board == 0) # 石が置かれていない場所を取得
for i in range(emp[0].size): # 石が置かれていない全ての座標に対して
p = (emp[0][i], emp[1][i]) # (i,j)座標に変換
if self.is_available(p):
pos.append(p) # 石が置ける場所の座標リストの生成
return pos
#石が置けるかをチェックする
def is_available(self, pos):
if self.board[pos[0], pos[1]] != NONE: # 既に石が置いてあれば,置けない
return False
opp = BLACK if self.turn == WHITE else WHITE
for di, dj in DIR: # 8方向の挟み(リバースできるか)チェック
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and self.board[i,j] == opp: #盤面に収まっており,かつ相手の石だったら
flag = True
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and self.board[i,j] != opp) or self.board[i,j] == NONE:
break
elif self.board[i,j] == self.turn and flag == True: # 自分と同じ色の石
return True
return False
#ゲーム終了チェック
def end_check(self):
if np.count_nonzero(self.board) == SIZE * SIZE or self.pss == 2: # ボードに全て石が埋まるか,双方がパスがしたら
self.game_end = True
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
self.winner = NONE
def legall_list(self):
legall_list = []
for i in range(36):
pos = divmod(i,6)
is_legall = self.is_available(pos)
if is_legall:
legall_list.append(i)
return legall_list
def choice_action(self,model,current_time_step):
value = model(current_time_step.observation) #設定したランダムポリシー
value = np.array(value[0][0])
value_dict = {}
max_value = -99999
for move in self.legall_list():
value_dict[move] = value[move]
if max_value < value[move]:
policy_step = move
max_value = value[move]
return ps.PolicyStep(action=tf.constant([policy_step]),state=(),info=())
#パスしたときの処理
def add_pass(self):
self.pss += 1
#パスした後の処理
def clear_pass(self):
self.pss = 0
@property
def batched(self):
return True
@property
def batch_size(self):
return 1
#ネットワークの設定
class MyQNetwork(network.Network):
def __init__(self, observation_spec, action_spec, n_hidden_channels=256, name='QNetwork'):
super(MyQNetwork,self).__init__(
input_tensor_spec=observation_spec,
state_spec=(),
name=name
)
n_action = action_spec.maximum - action_spec.minimum + 1
self.model = keras.Sequential(
[
keras.layers.Conv2D(4, 2, 1, activation='relu'),
keras.layers.Conv2D(8, 2, 1, activation='relu'),
keras.layers.Conv2D(16, 2, 1, activation='relu'),
keras.layers.Conv2D(32, 2, 1, activation='relu'), # 追加した
keras.layers.Dense(256, kernel_initializer='he_normal'),
keras.layers.Dense(256, kernel_initializer='he_normal'), #追加した
keras.layers.Flatten(),
keras.layers.Dense(n_action, kernel_initializer='he_normal'),
]
)
def call(self, observation, step_type=None, network_state=(), training=True):
observation = tf.cast(observation, tf.float32)
actions = self.model(observation, training=training)
return actions, network_state
#ランダム行動を行うときのポリシー
def random_policy_step(random_action_function):
random_act = random_action_function()
if random_act is not False:
return ps.PolicyStep(
action=tf.constant([random_act]),
state=(),
info=()
)
else:
raise Exception("No position avaliable.")
様々な実績を挙げている深層強化学習ですが,プログラムの書き方が悪いと全然学習が進まなかったりします. 6×6のオセロを学習するにあたって私が実際にした失敗をいくつか紹介します.
以下のコードで学習をさせることができます.
公開しているものは4万回ほど学習させたものです.
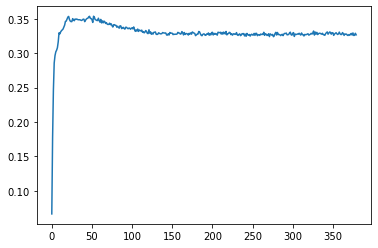
学習を進めると下のグラフのように誤差が減少していきます.
#環境の設定
env_py = Board()
env = tf_py_environment.TFPyEnvironment(env_py)
#黒と白の2つを宣言するために先に宣言
replay_buffer = {}
iterator = {}
n_step_update = 16
#ネットワークの設定
primary_network = MyQNetwork(env.observation_spec(), env.action_spec())
#エージェントの設定
agent = dqn_agent.DqnAgent(
env.time_step_spec(),
env.action_spec(),
q_network = primary_network,
optimizer = keras.optimizers.Adam(learning_rate=5e-4),
n_step_update = n_step_update,
target_update_period=1000,
gamma=0.99,
train_step_counter = tf.Variable(0),
epsilon_greedy = 0.0,
)
agent.initialize()
agent.train = common.function(agent.train)
#行動の設定
policy = agent.collect_policy
for role in [BLACK, WHITE]:#黒と白のそれぞれの設定
#データの保存の設定
replay_buffer[role] = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.collect_data_spec,
batch_size=env.batch_size,
max_length=10**6,
)
dataset = replay_buffer[role].as_dataset(
num_parallel_calls=tf.data.experimental.AUTOTUNE,
sample_batch_size=256,
num_steps=n_step_update+1,
).prefetch(tf.data.experimental.AUTOTUNE)
iterator[role] = iter(dataset)
#ポリシーの保存設定
tf_policy_saver = policy_saver.PolicySaver(agent.policy)
# 自己対局
tf_policy_saver.save("policy_0000")
num_episodes = 40000
decay_episodes = 5000
epsilon = np.concatenate( [np.linspace(start=1.0, stop=0.1, num=decay_episodes),0.1 * np.ones(shape=(num_episodes-decay_episodes,)),],0)
action_step_counter = 0
action_step_counter_white = 0
replay_start_size = 100
winner_counter = {BLACK:0, WHITE:0, NONE:0}#黒と白の勝った回数と引き分けの回数
episode_average_loss = {BLACK:[], WHITE:[]}#黒と白の平均loss
AL_list = []
for episode in range(1, num_episodes + 1):
policy._epsilon = 0
env.reset()
rewards = {BLACK:0, WHITE:0}# 報酬リセット
previous_time_step = {BLACK:None, WHITE:None}
previous_policy_step = {BLACK:None, WHITE:None}
while not env.game_end: # ゲームが終わるまで繰り返す
if not env.available_pos:# 石が置けない場合はパス
env.add_pass()
env.end_check()
else:# 石を置く処理
current_time_step = env.current_time_step()
while True: # 置ける場所が見つかるまで繰り返す
if previous_time_step[env.turn] is None:#1手目は学習データを作らない
pass
else:
previous_step_reward = tf.constant([rewards[env.turn],],dtype=tf.float32)
current_time_step = current_time_step._replace(reward=previous_step_reward)
traj = trajectory.from_transition( previous_time_step[env.turn], previous_policy_step[env.turn], current_time_step )#データの生成
replay_buffer[env.turn].add_batch( traj )#データの保存
if action_step_counter >= 2*replay_start_size:#事前データ作成用
experience, _ = next(iterator[env.turn])
loss_info = agent.train(experience=experience)#学習
episode_average_loss[env.turn].append(loss_info.loss.numpy())
else:
action_step_counter += 1
if random.random() < epsilon[episode]:#ε-greedy法によるランダム動作
policy_step = random_policy_step(env.random_action)#設定したランダムポリシー
else:
policy_step = env.choice_action(primary_network,env.current_time_step())
previous_time_step[env.turn] = current_time_step#1つ前の状態の保存
previous_policy_step[env.turn] = policy_step#1つ前の行動の保存
pos = policy_step.action.numpy()[0]
pos = divmod(pos, SIZE) # 座標を2次元(i,j)に変換
if env.is_available(pos):
rewards[env.turn] = 0
break
else:
rewards[env.turn] = REWARD_LOSE # 石が置けない場所であれば負の報酬
env.step(policy_step.action)# 石を配置
env.clear_pass() # 石が配置できた場合にはパスフラグをリセットしておく(双方が連続パスするとゲーム終了する)
if env.game_end:#ゲーム終了時の処理
if env.winner == BLACK:#黒が勝った場合
rewards[BLACK] = REWARD_WIN # 黒の勝ち報酬
rewards[WHITE] = REWARD_LOSE # 白の負け報酬
winner_counter[BLACK] += 1
elif env.winner == WHITE:#白が勝った場合
rewards[BLACK] = REWARD_LOSE
rewards[WHITE] = REWARD_WIN
winner_counter[WHITE] += 1
else:#引き分けの場合
winner_counter[NONE] += 1
#エピソードを終了して学習
final_time_step = env.current_time_step()#最後の状態の呼び出し
for role in [BLACK,WHITE]:
final_time_step = final_time_step._replace(step_type = tf.constant([2], dtype=tf.int32), reward = tf.constant([rewards[role]], dtype=tf.float32), )#最後の状態の報酬の変更
traj = trajectory.from_transition( previous_time_step[role], previous_policy_step[role], final_time_step )#データの生成
replay_buffer[role].add_batch( traj )#事前データ作成用
if action_step_counter >= 2*replay_start_size:
experience, _ = next(iterator[role])
loss_info = agent.train(experience=experience)
episode_average_loss[role].append(loss_info.loss.numpy())
else:
env.change_turn()
# 学習の進捗表示 (100エピソードごと)
if episode % 100 == 0:
print(datetime.datetime.now())
print(f'==== Episode {episode}: black win {winner_counter[BLACK]}, white win {winner_counter[WHITE]}, draw {winner_counter[NONE]}====')
if len(episode_average_loss[BLACK]) == 0:
episode_average_loss[BLACK].append(0)
print(f' AL: {np.mean(episode_average_loss[BLACK]):.4f}, PE:{epsilon[episode]:.6f}')
AL_list.append(np.mean(episode_average_loss[BLACK]))
if len(episode_average_loss[WHITE]) == 0:
episode_average_loss[WHITE].append(0)
print(f' AL: {np.mean(episode_average_loss[WHITE]):.4f}, PE:{epsilon[episode]:.6f}')
# カウンタ変数の初期化
winner_counter = {BLACK:0, WHITE:0, NONE:0}
episode_average_loss = {WHITE:[], BLACK:[]}
if episode % 1000 == 0:
tf_policy_saver.save(f"./policies/policy_{episode}")
# networkの保存 tensorflow-js用
primary_network.model.save(f'./checkpoints/NET_{episode}')
plt.plot(AL_list)
plt.show()
以下のコードでプレイすることができます.
import os
import numpy as np
import random
import copy
import datetime
import tensorflow as tf
from tensorflow import keras
import pygame
from pygame.locals import QUIT,KEYDOWN,K_LEFT,K_RIGHT,K_DOWN,K_UP,Rect,MOUSEBUTTONDOWN
MODEL = keras.models.load_model("checkpoints/NET_40000")
'''
リバーシプログラム:エージェント学習プログラム(CNN,DQNを利用)
Copyright(c) 2020 Koji Makino and Hiromitsu Nishizaki All Rights Reserved.
'''
import tensorflow as tf
from tensorflow import keras
from tf_agents.environments import gym_wrapper, py_environment, tf_py_environment
from tf_agents.agents.dqn import dqn_agent
from tf_agents.networks import network
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.policies import policy_saver
from tf_agents.trajectories import time_step as ts
from tf_agents.trajectories import trajectory, policy_step as ps
from tf_agents.specs import array_spec
from tf_agents.utils import common, nest_utils
import numpy as np
import random
import copy
import matplotlib.pyplot as plt
import datetime
SIZE = 6 # 盤面のサイズ SIZE*SIZE
NONE = 0 # 盤面のある座標にある石:なし
BLACK = 1# 盤面のある座標にある石:黒
WHITE = 2# 盤面のある座標にある石:白
STONE = {NONE:" ", BLACK:"●", WHITE:"○"}# 石の表示用
ROWLABEL = {'a':1, 'b':2, 'c':3, 'd':4, 'e':5, 'f':6, 'g':7, 'h':8} #ボードの横軸ラベル
N2L = ['', 'a', 'b', 'c', 'd', 'e', 'f', 'g', 'h'] # 横軸ラベルの逆引き用
REWARD_WIN = 1 # 勝ったときの報酬
REWARD_LOSE = -1 # 負けたときの報酬
# 2次元のボード上での隣接8方向の定義(左から,上,右上,右,右下,下,左下,左,左上)
DIR = ((-1,0), (-1,1), (0,1), (1,1), (1,0), (1, -1), (0,-1), (-1,-1))
#シミュレータークラス
class Board(py_environment.PyEnvironment):
def __init__(self):
super(Board, self).__init__()
self._observation_spec = array_spec.BoundedArraySpec(
shape=(SIZE,SIZE,1), dtype=np.float32, minimum=0, maximum=2
)
self._action_spec = array_spec.BoundedArraySpec(
shape=(), dtype=np.int32, minimum=0, maximum=SIZE*SIZE-1
)
self.reset()
def observation_spec(self):
return self._observation_spec
def action_spec(self):
return self._action_spec
#ボードの初期化
def _reset(self):
self.board = np.zeros((SIZE, SIZE, 1), dtype=np.float32) # 全ての石をクリア.ボードは2次元配列(i, j)で定義する.
mid = SIZE // 2 # 真ん中の基準ポジション
# 初期4つの石を配置
self.board[mid, mid] = WHITE
self.board[mid-1, mid-1] = WHITE
self.board[mid-1, mid] = BLACK
self.board[mid, mid-1] = BLACK
self.winner = NONE # 勝者
self.turn = random.choice([BLACK,WHITE])
self.game_end = False # ゲーム終了チェックフラグ
self.pss = 0 # パスチェック用フラグ.双方がパスをするとゲーム終了
self.nofb = 0 # ボード上の黒石の数
self.nofw = 0 # ボード上の白石の数
self.available_pos = self.search_positions() # self.turnの石が置ける場所のリスト
image2 = np.zeros((SIZE,SIZE,1),"float32")
if self.turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
image2[self.board==self.turn] = 1
image2[self.board==enemy_turn] = 2
time_step = ts.restart(image2)
return nest_utils.batch_nested_array(time_step)
#行動による状態変化(石を置く&リバース処理)
def _step(self, pos):
pos = nest_utils.unbatch_nested_array(pos)
pos = divmod(pos, SIZE)
if self.is_available(pos):
self.board[pos[0], pos[1]] = self.turn
self.do_reverse(pos) # リバース
self.end_check()#終了したかチェック
image2 = np.zeros((SIZE,SIZE,1),"float32")
if self.turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
image2[self.board==self.turn] = 1
image2[self.board==enemy_turn] = 2
time_step = ts.transition(image2, reward=0, discount=1)
return nest_utils.batch_nested_array(time_step)
#ターンチェンジ
def change_turn(self, role=None):
if role is NONE:
role = random.choice([WHITE,BLACK])
if role is None or role != self.turn:
self.turn = WHITE if self.turn == BLACK else BLACK
self.available_pos = self.search_positions() # 石が置ける場所を探索しておく
#ランダムに石を置く場所を決める(ε-greedy用)
def random_action(self):
if len(self.available_pos) > 0:
pos = random.choice(self.available_pos) # 置く場所をランダムに決める
pos = pos[0] * SIZE + pos[1] # 1次元座標に変換(NNの教師データは1次元でないといけない)
return pos
return False # 置く場所なし
#リバース処理
def do_reverse(self, pos):
for di, dj in DIR:
opp = BLACK if self.turn == WHITE else WHITE # 対戦相手の石
boardcopy = self.board.copy() # 一旦ボードをコピーする(copyを使わないと参照渡しになるので注意)
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and boardcopy[i,j] == opp: # 盤面に収まっており,かつ相手の石だったら
flag = True
boardcopy[i,j] = self.turn # 自分の石にひっくり返す
# 元のやつは or self.board[i,j] == NONE が抜けている!!!!!
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and boardcopy[i,j] != opp) or self.board[i,j] == NONE:
break
elif boardcopy[i,j] == self.turn and flag == True: # 自分と同じ色の石がくれば挟んでいるのでリバース処理を確定
self.board = boardcopy.copy() # ボードを更新
break
#石が置ける場所をリストアップする.石が置ける場所がなければ「パス」となる
def search_positions(self):
pos = []
emp = np.where(self.board == 0) # 石が置かれていない場所を取得
for i in range(emp[0].size): # 石が置かれていない全ての座標に対して
p = (emp[0][i], emp[1][i]) # (i,j)座標に変換
if self.is_available(p):
pos.append(p) # 石が置ける場所の座標リストの生成
return pos
#石が置けるかをチェックする
def is_available(self, pos):
if self.board[pos[0], pos[1]] != NONE: # 既に石が置いてあれば,置けない
return False
opp = BLACK if self.turn == WHITE else WHITE
for di, dj in DIR: # 8方向の挟み(リバースできるか)チェック
i = pos[0]
j = pos[1]
flag = False # 挟み判定用フラグ
while 0 <= i < SIZE and 0 <= j < SIZE: # (i,j)座標が盤面内に収まっている間繰り返す
i += di # i座標(縦)をずらす
j += dj # j座標(横)をずらす
if 0 <= i < SIZE and 0 <= j < SIZE and self.board[i,j] == opp: #盤面に収まっており,かつ相手の石だったら
flag = True
elif not(0 <= i < SIZE and 0 <= j < SIZE) or (flag == False and self.board[i,j] != opp) or self.board[i,j] == NONE:
break
elif self.board[i,j] == self.turn and flag == True: # 自分と同じ色の石
return True
return False
#ゲーム終了チェック
def end_check(self):
if np.count_nonzero(self.board) == SIZE * SIZE or self.pss == 2: # ボードに全て石が埋まるか,双方がパスがしたら
self.game_end = True
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
self.winner = NONE
#ボードの表示(人間との対戦用)
def show_board(self):
print(' ', end='')
for i in range(1, SIZE + 1):
print(f' {N2L[i]}', end='') # 横軸ラベル表示
print('')
for i in range(0, SIZE):
print(f'{i+1:2d} ', end='')
for j in range(0, SIZE):
print(f'{STONE[int(self.board[i][j])]} ', end='')
print('')
def legall_list(self):
legall_list = []
for i in range(36):
pos = divmod(i,6)
is_legall = self.is_available(pos)
if is_legall:
legall_list.append(i)
return legall_list
def judge(self):
self.nofb = len(np.where(self.board==BLACK)[0])
self.nofw = len(np.where(self.board==WHITE)[0])
if self.nofb > self.nofw:
self.winner = BLACK
elif self.nofb < self.nofw:
self.winner = WHITE
else:
# 引き分けを3にした
self.winner = 3
return self.winner
#パスしたときの処理
def add_pass(self):
self.pss += 1
#パスした後の処理
def clear_pass(self):
self.pss = 0
@property
def batched(self):
return True
@property
def batch_size(self):
return 1
#ランダム行動を行うときのポリシー
def random_policy_step(random_action_function):
random_act = random_action_function()
if random_act is not False:
return random_act
else:
raise Exception("No position avaliable.")
# 左上から順に埋めていく
def position_search(pos_x,pos_y):
return pos_x//50,pos_y//50
def play_othello():
my_turn = int(input("BLACK:1, WHITE:2"))
if my_turn == 1:
enemy_turn = 2
else:
enemy_turn = 1
pygame.init()
pygame.key.set_repeat(5,5)
width = 300
hight = 300
surface = pygame.display.set_mode((width,hight))
fpsclock = pygame.time.Clock()
env = Board()
color = 1
fps = 10
myfont = pygame.font.SysFont(None, 40)
while True:
for event in pygame.event.get():
steped = False
if event.type == QUIT:
pygame.quit()
sys.exit()
elif True: # 自分のターンの処理
current_time_step = env.current_time_step()
if not env.legall_list():# 石が置けない場合はパス
env.add_pass()
env.end_check()
steped = True
else:# 石を置く処理
if env.turn == enemy_turn:
print("###########")
steped = True
# print(current_time_step)
value = MODEL(current_time_step.observation) #設定したランダムポリシー
value = np.array(value)
value_dict = {}
max_value = -99999
for move in env.legall_list():
value_dict[move] = value[0][move]
if max_value < value[0][move]:
policy_step = move
max_value = value[0][move]
print(value_dict)
print(policy_step)
# policy_step = np.argmax(value)
if not policy_step in env.legall_list():
policy_step = random_policy_step(env.random_action)
print("random")
env.step(policy_step)# 石を配置
else:
if event.type == MOUSEBUTTONDOWN:
pos_x,pos_y = event.pos
row,col = position_search(pos_x,pos_y)
# print(row*8+col,env.legall_list(),row*8+col in env.legall_list())
while True:
if row*6+col in env.legall_list():
policy_step = row*6+col
steped = True
env.step(policy_step)# 石を配置
break
else:
break
if steped:
print(env.turn,policy_step)
env.clear_pass() # 石が配置できた場合にはパスフラグをリセットしておく(双方が連続パスするとゲーム終了する)
if env.game_end:#ゲーム終了時の処理
result = env.judge()
print("result",result)
else:
# print(steped)
if steped:
env.change_turn()
surface.fill((0,255,20))
# 盤面の描画をする
for i in range(1,6):
pygame.draw.line(surface, (0,0,0), (0,i*50), (400,i*50), width=1)
pygame.draw.line(surface, (0,0,0), (i*50,0), (i*50,400), width=1)
# 石を描画する
for x in range(6):
for y in range(6):
if env.board[x][y] == 1:
pygame.draw.circle(surface, (0,0,0), (50*x+25,50*y+25), 18, width=0)
elif env.board[x][y] == 2:
pygame.draw.circle(surface, (255,255,255), (50*x+25,50*y+25), 18, width=0)
# 置けるところを描画する
if color == 2:
for i in range(len(valid_hand)):
pygame.draw.circle(surface, (0,0,255), (50*valid_hand[i][0]+25,50*valid_hand[i][1]+25), 5, width=0)
pygame.display.update()
fpsclock.tick(fps)
play_othello()
何も考えないでプレイすると勝ったり負けたり程度の強さにはなりました. 探索をまったく行わない状態でこの程度の強さなので探索を行うようにすればもう少し強いものを作ることができます.
深層強化学習を利用して6×6のオセロのAIを作ることができました. また,この記事は『TensorFlowによる深層強化学習入門』の4章を参考にしました. より詳しく学ばれたい方やTF-Agentsによる深層強化学習の実装例をもっと見たい方は読まれるといいかもしれません.